智东西
作者 | 王涵
编辑 | 漠影
智东西在5月20日报道,继2025年4月25日的Create 2025 AI开发者大会上,百度推出了文心大模型4.5 Turbo和X1 Turbo之后,今天他们又对相关技术成果进行了深入分析和数据更新。
在此次活动中,百度的副总裁吴甜与中国信息通信研究院的人工智能研究所工程化部主任曹峰,还有用户代表们一起,分享了文心大模型的最新技术进展、全球大模型的发展趋势以及大模型的能力评测和使用体验等内容。

回顾一下,4月25日,百度的创始人李彦宏在Create 2025大会上正式推出了文心大模型4.5 Turbo和X1 Turbo两个新版本。他提到,当时市场上有些模型仍然存在单一模态、幻觉率高、反应慢和使用成本高的问题。为了打破这些瓶颈,百度推出了具备多模态交互能力、强推理性能和低成本优势的新一代文心大模型。
一个月后,百度通过AI开放日活动进一步分享了新模型的技术要点。吴甜在解读时强调,文心大模型4.5 Turbo在多模态训练效率上提升了1.98倍,已经为超过700万名开发者提供了支持。中国信通院主任曹峰还现场宣布,文心大模型X1 Turbo成为国内首个通过可信AI大模型推理能力评估的大模型。
一、学习效果提高1.98倍,多模态理解效果提升31.21%
文心大模型4.5 Turbo是基于4.5版本的多模态大模型,针对不同模态数据在结构、规模和知识密度上的差异,通过多模态异构专家建模、自适应分辨率视觉编码、时空重排列的三维旋转位置编码以及自适应模态感知损失计算等技术进行了全面升级。
百度副总裁吴甜表示,这一升级显著提升了跨模态学习效率和多模态融合效果,学习效率提升了1.98倍,而多模态理解效果提高了31.21%。

吴甜副总裁在技术创新方面进行了详细讲解
在后续训练上,吴甜提到百度研发了一种自反馈增强的技术框架,依托大模型自身的生成与评估反馈能力,实现了“训练-生成-反馈-增强”的模型迭代闭环。
她还提到,在训练阶段,文心通过融合偏好学习的强化学习技术,建立了多元统一奖励机制,从而提升了对结果质量判定的准确度。这个多元统一的奖励机制涵盖了答案的正确性、执行反馈、思路深度、指令遵循、工具调用合理性和回答多样性等多个维度,指导模型行为向更优的方向发展。
深入了解文心大模型的训练机制与应用
说到文心大模型的训练,大家一定想知道它是怎么模拟人类的思维过程的。其实,文心采用了多种思考和行动的路径,比如边思考边行动、先考虑后执行、以及行动后进行反思和调整等。这种灵活的方式,加上一个全面的奖励机制,让模型在思考和行动的各个环节都能优化,最终提升了它在不同领域解决问题的能力。
说到数据的重要性,吴甜强调了这一点。她提到,文心大模型通过一个闭环流程,进行数据的挖掘、合成、分析和评估,确保训练数据的质量。采用第一性原理驱动,加上对稀缺数据的挖掘和线上反馈的融合,这样的组合让训练数据变得更加高效。同时,在多模态数据建设方面,动态平行数据的构建以及视觉知识的引入,进一步增强了不同模态之间的信息共享。
在会议上,吴甜还展示了文心大模型4.5 Turbo的多模态处理和理解能力,包括高精度的OCR和翻译、复杂的绘图任务处理、视频内容解析,以及多模态解题能力,真是让人眼前一亮。
二、代码智能体的广泛应用与飞桨3.0的升级
吴甜在演讲中提到,大模型的能力不断扩大,效率也在提升,这为更具前瞻性和创新性的应用打开了新思路。
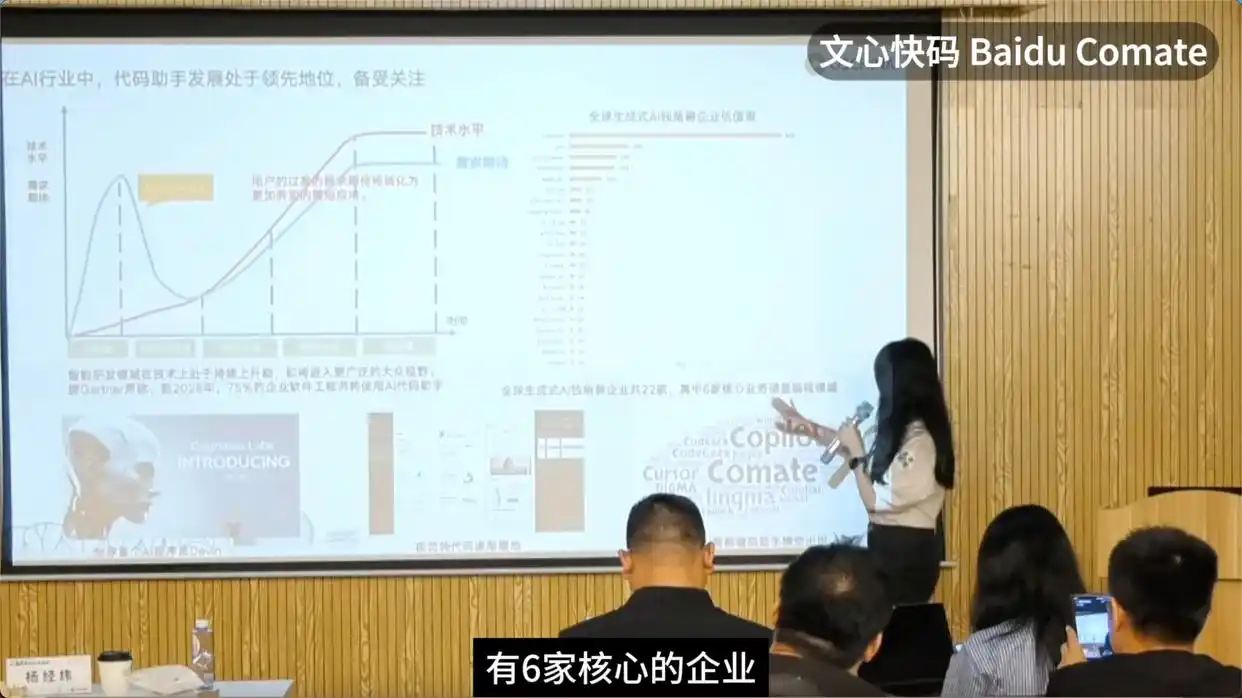
在代码领域,百度利用文心大模型的语言与代码能力,推出了代码智能体和智能代码助手——文心快码。根据最新数据,文心快码生成的代码在百度每天新增的代码中占比已超过40%。而且文心快码已经向社会开放,目前已服务超760万名开发者,真正实现了代码的智能化。
在数字人领域,吴甜分享了百度研发的“剧本”驱动多模协同的超拟真数字人技术,这项技术通过语言、声音和形象的协调一致,已经应用于超过10万个数字人主播,直播转化率提升了31%,而直播开播的成本更是下降了80%!

而且,她还特别提到,文心大模型在能力扩展和效率提升方面,得益于飞桨文心的联合优化。这不仅涉及到框架模型的优化,还包括算力的提升。通过技术创新,文心4.5 Turbo的训练吞吐量达到了文心4.5的5.4倍,而推理的吞吐量更是达到了8倍。
据了解,飞桨和文心生态圈目前已经聚集了2185万名开发者、67万家企事业单位,以及110万个模型,并且建立了7个产业赋能中心、7个教育创新中心和2个数据生态中心。

三、从分析到生成:全球大模型能力演进现状
中国信通院人工智能研究所的曹峰主任,分享了全球大模型能力的演进现状和未来趋势,还对文心大模型的推理能力进行了详细解读。
曹峰提到,自2017年以来,人工智能在很多领域已经超越了人类的能力。到2022年,大模型技术开始崭露头角,推动了人工智能能力的快速提升,特别是在多任务理解、代码处理和多模态理解等方面都取得了显著进展。这些大模型不仅增强了基本功能,还衍生出诸如文档编写、代码生成、视频和图像制作等新能力。

中国信通院人工智能研究所的曹峰主任在会上发表演讲
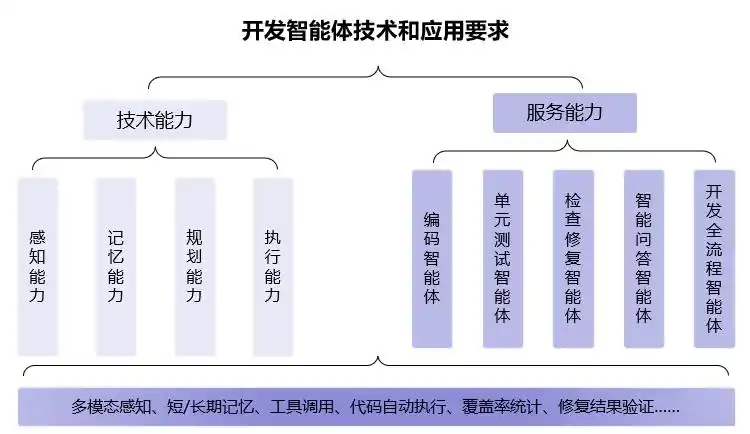
在文档编写方面,大模型已经从简单的文案生成扩展到复杂的论文写作,极大提升了内容创作的效率与质量。曹峰指出,大模型在代码编写上也不再局限于基础编程,而是深度融入到软件开发的各个环节,包括代码解释、添加注释、错误检查以及生成测试用例,极大地提升了软件开发的智能化水平。
此外,这些大模型在科研领域展现了巨大的潜力,尤其是在生物医药和材料研发等前沿领域,推动了科研的进展,同时也显著提高了自动驾驶仿真技术的精准度和可靠性。

四、大模型发展趋势:更聪明、更便宜、更专业
曹峰表示,大模型的发展趋势主要体现在三个方面:一是更聪明,二是训练和推理的成本更低,三是不断涌现出大量更专业的模型,同时推理模型也开始内置思维链,并朝着多模态方向发展。
未来的大模型发展方向!
曹峰提到,基础模型在规模和性能上都在稳步提升,而推理模型在处理复杂推理和数学问题上表现得越来越出色。通过优化架构,如今大模型的训练和推理成本也大幅降低,推理成本甚至比早期减少了90%。
随着技术的不断进步,行业内涌现出许多专业模型,比如代码模型和科学模型等,这些模型在特定领域中表现得相当出色;而推理模型则将人类的思维过程融入其中,进一步提升了专业知识的应用能力。多模态模型则尝试将生成与理解能力结合,并探索强化学习的融入,以增强其思考能力。
尽管当前的大模型能力大幅提升,但它们仍然面临一些挑战,比如难以解释的特性、在高确定性场景下容易产生幻觉的问题、实时学习的困难,以及在特定情况下获取数据的难题等。
国内首款文心X1 Turbo获得可信AI大模型推理能力评估
在演讲中,曹峰指出,大模型的输出结果评估方法正在迅速发展。在进行大模型基准测试时,评估模型结果的方式至关重要,通常分为人工评估、自动化评估和大模型作为裁判这三种,其中使用能力最强的大模型代替人工评估的方法备受关注。
大模型的评测机制和体系也在不断创新,其测试技术的关键创新包括自动挖掘模型缺陷、真实场景测试、高水平测试数据以及人机对齐的裁判模型。
曹峰认为,基础模型还在向多维方向扩展。展望2024年,大模型已经从语言模型拓展到深度复杂推理和多模态能力的提升。这包括多模态能力的边界拓展和端侧部署的加速应用。对于2025年,他预测,随着大模型技术的不断创新,多模态和复杂推理将继续迎来突破,端侧应用将加速落地,垂直领域的深耕将更加精准,具身智能将逐渐崭露头角,共同推动产业的升级。
结尾:技术的真正价值在于服务用户
在大会的最后,百度邀请了一位特别的嘉宾,他是一名16岁的大语言模型用户。通过分享自己的亲身体验,他讲述了大语言模型如何在日常生活中带来了实实在在的变化。
回想起人工智能技术刚起步的时候,大家讨论的主要是它可能带来的影响,比如是否会取代工作,甚至可能威胁到人类的地位。但这位年轻用户的故事,从个人的角度展示了人工智能在普通人生活中的真实应用。
当大模型能够像人一样理解世界、思考问题并自我升级时,技术的进步就会真正转化为社会的共同利益。正如这位用户所说:“技术的魅力不在于让谁惊叹,而是能解决一个又一个真实的问题……AI的大门已经打开了,关键是你愿不愿意走进去。”