代码大模型:软件开发的新风口
在如今这个数字时代,人工智能的大模型正在以前所未有的速度影响着各行各业,尤其是软件开发这一块。写代码是软件开发的核心,而现在我们看到的趋势是从传统的人工编写代码转向人机合作,甚至智能生成代码。比如,百度推出的“文心快码”,就像一颗小石子投入水中,瞬间引发了广泛的关注和讨论,让整个行业再次聚焦于代码大模型。如果我们仔细研究一下“文心快码”,再看看其他地方在这个领域的最新进展,对于理解未来的软件开发方向和提升行业效率,会大有裨益。

文心快码:代码生成的利器
说到百度的“文心快码”,这可真是他们在代码生成领域的一次重要尝试!这个工具的亮点不少,依托于百度强大的技术和丰富的数据资源,生成代码的速度和准确性都非常不错。比如,如果你想用 Python 处理一些数据分析的任务,只需简单描述你的需求,比如“从一个包含用户行为的 CSV 文件中,计算每个用户的操作次数,并按次数排序,最后保存为新的 CSV 文件”。文心快码就能迅速理解你的意图,给你提供一个靠谱的代码框架。
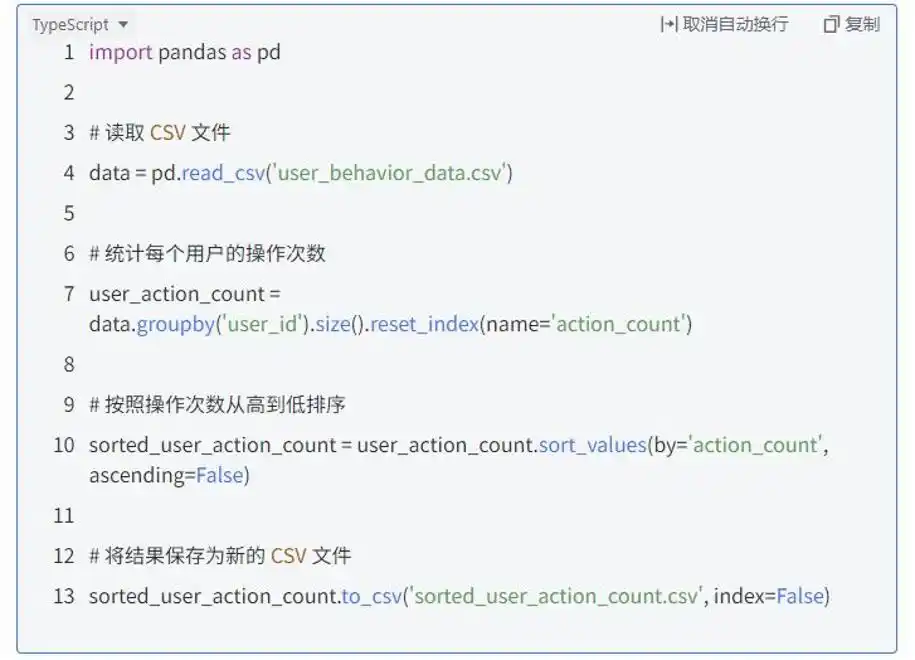
提升开发效率的文心快码
这段生成的代码简直完美,语法正确,逻辑清晰,从数据读取、处理到结果存储,整个流程毫不费力,开发者因此省下了大量时间,不必再去操心那些基本的细节。
此外,文心快码在处理复杂代码时也非常出色。开发者在写代码时,有时可能会忘记某个函数的参数怎么用,或者不确定某个编程方式的正确用法。比如,当使用 Python 的 requests 库发送网络请求时,忘了超时参数的具体位置和格式,文心快码会根据你写的代码情况,提供恰当的提示,帮助你快速完成补全。
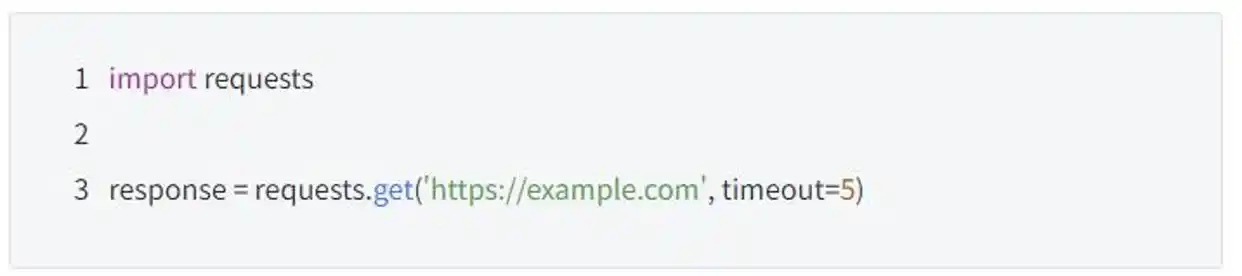
Codestral模型的强势崛起
有了这种实时、精准的代码补全,开发者在写代码时不再需要频繁查阅文档,整个过程变得顺畅很多。放眼全球,代码大模型的热潮正如火如荼,许多科技巨头及新兴的 AI 公司纷纷涌入,不断推出新模型和技术,推动代码生成技术的不断进步。
来自法国的 Mistral AI 公司推出的 Codestral 系列模型在业内引起了热烈反响。以 Codestral 25.01 为例,它在架构设计和分词器优化上都有显著改进,代码生成和补全的速度比之前快了近一倍。它支持超过 80 种编程语言,无论是 Python、Java、C++ 还是一些冷门的 Fortran,都能轻松应对。在性能方面,Codestral 25.01 在 HumanEval 基准测试中,Python 代码生成得分高达 86.6%;处理 SQL 的 Spider 基准测试中得分也有 66.5%;在多语言综合测试中,平均得分达到了 71.4%,这表明它不仅具备强大的通用性,还有出色的代码生成能力。
国内外代码大模型的精彩表现
在国内,字节跳动在代码大模型方面同样表现不俗。他们的一些模型在理解和生成代码的能力上极具优势,尤其是在处理复杂的代码库时,简直是得心应手。比如,当需要维护一个大型电商系统的后端代码库时,这个模型能够迅速理清代码结构,识别潜在的漏洞和性能瓶颈,甚至给出优化建议。如果它发现某个数据库查询在高并发情况下可能会导致锁表问题,它会参考大量类似代码案例,建议使用异步查询或连接池优化,从而提升代码的稳定性和响应速度。
在开源社区,大家也合作推出了不少优秀的代码大模型。比如,月之暗面(Moonshot AI)团队的 Kimi-Dev-72B 模型在 SWE-bench Verified 编程基准测试中获得了 60.4% 的高分,超越了许多参数量巨大的新版本 DeepSeek-R1,成为全球开源模型的领军者。这个 Kimi-Dev-72B 模型创新性地结合了 BugFixer 和 TestWriter,通过大规模的中期训练和强化学习,在修复代码错误和编写测试用例方面表现出色,为开源代码大模型的发展开辟了新路。
从技术角度看,现在的代码大模型在多个重要领域都取得了突破性进展。
代码理解、程序合成与多语言支持的进步
谈到代码理解,现在的模型真是越来越强大!它们不仅能理解代码的含义,还能清晰地识别代码结构,这得益于越来越复杂高效的神经网络设计,以及大规模的代码库预训练。如今,这些模型能够精准分析代码背后的深层逻辑。举个例子,以前那些复杂的递归算法代码,它们能理解递归结束条件和递归调用之间的关系,这让生成代码变得更靠谱,能够真正按照开发者的思路生成代码。
程序合成方面的进展同样令人振奋。像 AlphaCodium 这种迭代式解题框架,不再是简单拼凑几段代码,而是先分析问题,再一步步构建一个完整、可运行的程序。比如在处理需要既设计图形界面又进行数据处理的任务时,它会先规划好界面的样子,然后再逐步加入数据处理部分,最终生成一个完整的程序。
而在多语言支持方面,进步也是显而易见的。Salesforce 的 CodeGen2 这个拥有 70 亿参数的多语言模型,简直如同语言达人,能在不同编程语言间自如切换。假如你有一段用 Python 写的数据分析代码,想转换成 Java 版本,这个模型能快速理解 Python 代码的功能,并生成一份完全相同的 Java 代码,从而让不同编程语言之间的沟通变得更加顺畅。
代码大模型面临的挑战
尽管代码大模型已经取得了显著成果,但要想实现更广泛和深入的应用,还有不少难题需要解决。
首先是代码正确性验证的问题。代码的复杂性意味着,逻辑上任何小错误都可能导致严重后果。比如,如果让模型编写涉及用户数据加密和传输的代码,可能因为对加密算法理解不够深刻或未完全遵循安全规范而产生安全隐患。现在,大家正努力将严谨的数学验证方法与大模型结合,希望能通过数学手段确保代码的安全性,不过这个技术仍在发展中,效率和适用范围有待改进。
此外,大模型在实时响应方面的优化也是个大问题。许多开发者希望代码生成工具能快速反馈,理想情况下输入需求后立刻得到结果。然而,随着模型变得越来越大、越来越复杂,推导代码的速度却可能变慢,直接影响用户体验。因此,如何在不牺牲模型效果的前提下,通过更好的硬件配置或优化算法提高推导速度,成为亟待解决的难题。
代码大模型的技术融合与场景拓展
展望未来,代码大模型在技术融合和应用场景方面无疑会迎来更大的突破。首先,在技术融合方面,软件开发的各个环节,如版本控制、项目管理、测试自动化等,模型都能深入结合。例如,与版本控制系统结合后,它可以根据代码历史修改记录,自动生成智能的代码变更说明;在项目管理中,它还能根据项目需求和进度,合理安排开发任务。
再来说说应用场景,除了传统软件开发领域,代码大模型在智能硬件开发、自动化运维、工业控制编程等新兴领域也能发挥重要作用,助力各行业加快数字化转型的步伐。