
说到一家还没盈利的AI公司,竟然在短短三个月内发布了三个模型,结果中国前十大互联网公司中有九家争先恐后地想要接入,这是不是听起来很神奇呢?
4月8日,智谱AI在广州推出了它的最新开源大模型GLM-5.1。这是继2月12日发布的GLM-5和3月16日的GLM-5-Turbo之后的又一款。发布后,社交媒体和官网上,很多企业纷纷宣布“我们已经接入了”,从互联网巨头到云服务商、软件公司甚至芯片厂商,都在这个名单上,规模不一。
公开资料显示,GLM-5系列已经有至少18家企业宣布接入,覆盖了四个层次的公司:
在行业顶尖的互联网公司里,字节跳动(TRAE编程助手)、阿里巴巴(Qoder)、腾讯(CodeBuddy/WorkBuddy系列)、百度(智能云千帆平台)、美团(CatPaw)、快手(万擎)等都已完成集成。智谱在3月31日发布的首份财报中提到,“GLM-5发布后24小时内,就有字节跳动TRAE、阿里巴巴Qoder、腾讯CodeBuddy、美团CatPaw、快手万擎、百度智能云和WPS Office等头部产品的官方接入”,并强调“中国前十大互联网公司中已有九家深度集成GLM”。在GLM-5.1发布当天,腾讯迅速将其CodeBuddy和WorkBuddy系列升级到GLM-5.1,百度则宣布完成了“Day0全栈适配”,字节跳动TRAE也实现了同步首发。
在云服务商方面,华为云在发布当天就上线了码道(CodeArts)代码智能体,用户激增导致排队;金山云在4月10日上线了星流平台;而优刻得早在GLM-5阶段就完成了接入。
在软件与硬件领域,金山办公(WPS灵犀)、字节跳动的扣子Coze、模型路由平台OpenRouter、软通动力(机械革命“龙虾盒子”终端也搭载了GLM-5-Turbo)都通过深度集成、API接入和硬件搭载等多种方式实现了接入。值得关注的是,WPS灵犀的实际接入时间(2月12日)早于官方公告时间(2月14日),这说明一些企业在正式公布之前就已经完成了技术对接。
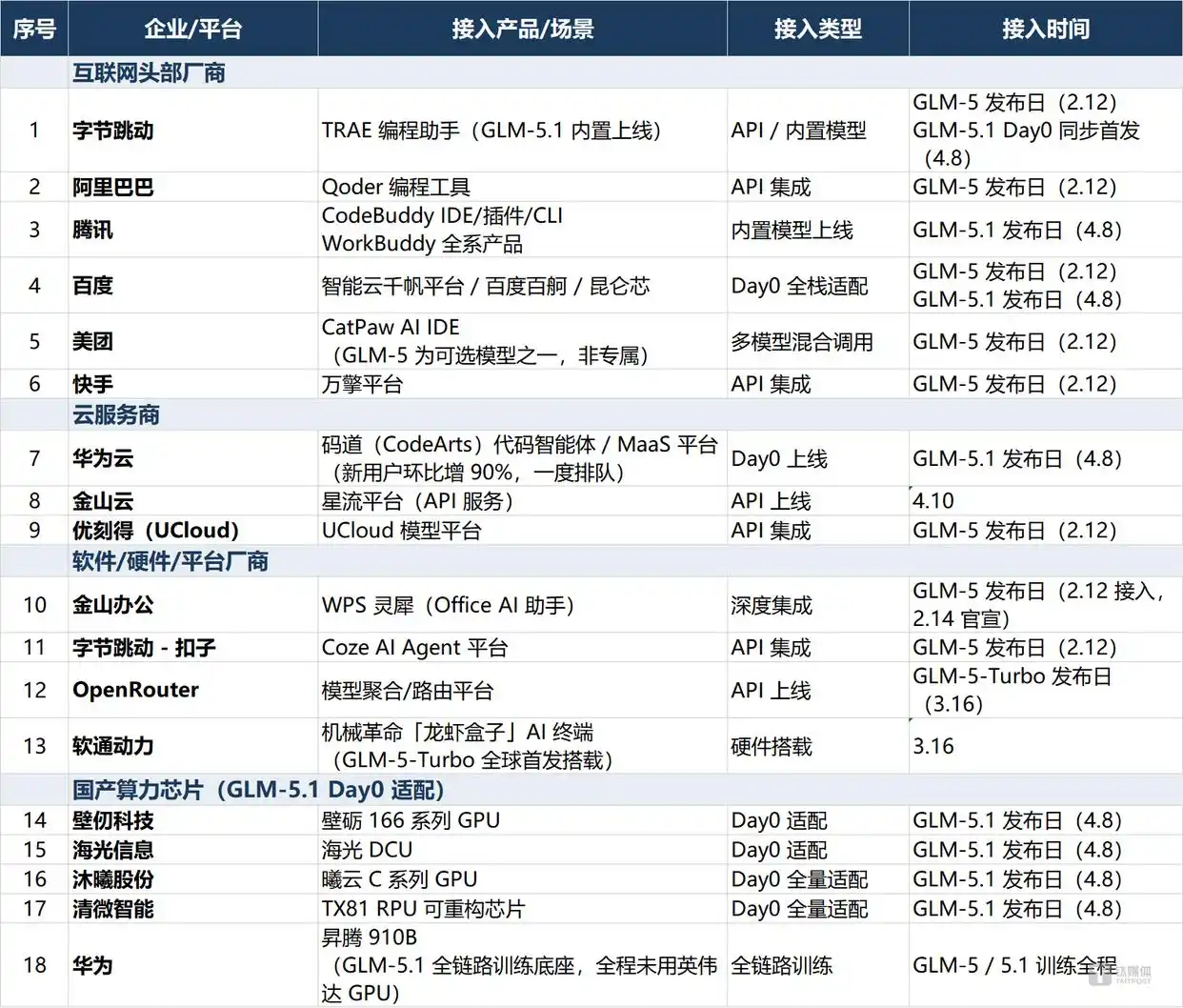
更让人瞩目的是国产算力芯片的集体“Day0适配”——壁仞科技(壁砺166系列)、海光信息(DCU)、沐曦股份(曦云C系列)、清微智能(TX81 RPU)在GLM-5.1发布当天宣布完成适配,这样加上华为昇腾910B,形成了一条完整的国产算力适配链条。
这种现象其实并不新鲜——每当国内的顶尖大模型发布,接入的公告总是如约而至。不过这一次,公告的频率和速度明显比以前要快,确实让人好奇:难道是模型真的很厉害,还是大家在做集体营销呢?
说实话,答案可能两者都有,但更深层的行业现实也在其中。GLM-5系列模型的接入潮,正好为我们提供了一个切入点,去理解“中国的大模型现在发展到什么阶段”。
为什么这么多企业选择“官宣”接入?
这个现象可以通过三条逻辑来解释。
第一,MIT开源协议大大降低了接入的成本和风险。 从GLM-4.5到GLM-5再到GLM-5.1,智谱的旗舰模型全都采用MIT协议开源——这意味着可以商用、可以私有化部署、没有使用限制。对于很多中小企业和政府机构来说,这种开源模式提供了无法替代的优势:数据可以留在内网,合规风险也能控制,采购审批也变得更简单。官宣接入的成本非常低,但理由却非常充足。
第二,编程能力的真实突破,给了部分企业接入的产品价值支撑。 GLM-5.1在SWE-Bench Pro编程测试中取得了58.4分,超越了Claude Opus 4.6(57.3分)和GPT-5.4(57.7分),首次以国产开源模型的身份在这个基准上超越顶级闭源产品。对于软件开发类企业来说,编程能力的提升是非常直观的,接入不再是单纯的噱头,至少在编程场景上能找到实际使用的机会。
第三,“接入国产旗舰模型”本身就带有营销价值。 在政企采购、融资路演和媒体曝光的语境中,官宣接入头部大模型是一张门槛不高却信号明显的牌。这跟模型本身的能力关系不大,而是中国AI生态中的一种特有宣发风格。
这三条逻辑分别触及了技术、商业和生态三个层面的现实。要真正理解这些,需要从多个维度来拆解:GLM-5.1的技术现状如何,开源与闭源的竞争走到了哪一步,以及智谱的商业化进展如何。
突破是实实在在的,但“偏科”代价不小
先说说真实的进展。
GLM-5.1继续采用了GLM-5的MoE架构:总参数744B,256个专家混合,约44B的激活参数,并在全链路的华为昇腾910B上完成了训练。严格来说,这不算一次架构迭代,而是一种后训练阶段的定向优化——在编程和Agent场景中加强了强化学习的权重。从GLM-5到GLM-5.1,仅用了不到八周的时间,这个迭代速度本身就值得肯定。
核心的突破集中在两个方向。
其一,编程基准的显著提升。 SWE-Bench Pro的58.4分,超越了Claude Opus 4.6(57.3分)和GPT-5.4(57.7分),这是国产开源模型在这一基准上的历史最高分。在Terminal-Bench和NL2Repo两项代码评测中,GLM-5.1综合排名全球第三、国产第一、开源第一。
其二,“长程任务”的能力首次量化验证。 智谱将这个能力定义为模型在接到任务后持续工作数小时甚至更久的能力,官方展示了一些案例:模型在无监督状态下完成了655轮迭代、超过6000次工具调用,QPS从3,547提升至21,500;14小时内将GPU计算内核加速35.7倍;8小时内自主搭建了包含窗口管理器、终端模拟器、文件浏览器的完整Linux桌面。这种表现更像是一个初级工程师,而非高级搜索引擎。
不过,这里有两个必须注意的折扣。
折扣一:评测体系的可信度存在疑问。 今年3月,AI安全研究机构METR发布研究指出,SWE-bench系列中自动判定为“通过”的AI代码方案,约有一半会被真实项目维护者拒绝,自动评测可能将AI编程能力高估了7倍。几乎在同一时间,OpenAI宣布不再使用SWE-bench Verified作为评估标准,原因是自动评测与实际开发的效果偏差已变得不可忽视。GLM-5.1与Claude Opus 4.6之间不到1分的差距,可能就在METR揭示的误差范围内,因此“全球最强开源模型”的称号需要谨慎看待。
折扣二:能力分布非常不均匀。 Text Arena第三方竞技场的排名清晰地显示了这一代价:在编程领域上升了28名,但医疗领域下降了24名,法律下降了6名,数学下降了2名。在NL2Repo(从零构建代码仓库)上,GLM-5.1落后Claude Opus 4.6达7分(42.7对49.8)。知乎开发者“晴天”在阅读理解、SVG代码生成等方面进行的测试表明,GLM-5.1连基本的阅读理解都未达标;另一位通过Ollama本地部署的开发者则认为“整体不如Qwen3.6-Plus”。虽然这些个体测试不能代表整体,但都暗示了一个事实:GLM-5.1在编程和Agent方向上进行了重点训练,而在其他领域有所牺牲,成了一个“偏科生”。
当然,偏科并不一定是贬义,关键在于“偏的那个科”值不值得偏。
编程和自主执行,确实是AI行业竞争最激烈的赛道。但我们也要清楚地看到,就在GLM-5.1发布的同一天,Anthropic推出了Mythos Preview——这款模型在SWE-Bench Pro上得到了77.8分,领先GLM-5.1近20分。Mythos虽然还未公开,但它标定了行业能力的当前天花板,也反映出竞争对手的实力远比已发布的产品更强大。
开源换取信任,闭源则换取安全
GLM-5.1发布的那天,恰好发生了一件非常有趣的事情。
在太平洋的另一边,Anthropic宣布了新一代模型Claude Mythos Preview——但这次并没有向公众开放,而是选择了定向提供给苹果、微软、谷歌、英伟达等12个合作伙伴和40余家基础设施组织,用于一个名为“Project Glasswing”的网络安全计划。
同一天,两家公司各自出了一手牌,方向截然相反:一家将模型权重全部上传到Hugging Face供大家下载,而另一家则把最强的模型锁在了围墙内。
这个巧合,正好反映了当前AI行业最核心的路线分歧。
智谱的开源逻辑已经形成了一套清晰的商业飞轮:通过MIT协议开源建立开发者的信任→信任转化为企业采购时的优先考量→通过API调用和Agent执行收费实现盈利。这条路在中国的政企市场上有结构性的优势,数据合规要求高的行业(如金融、政务、医疗)对“数据不出内网”有刚性需求,而闭源API自然无法满足。
Anthropic的闭源策略与智谱的开源之路
说到Anthropic的闭源模式,它的逻辑完全不同。它把安全性作为品牌的核心卖点,通过强大的能力来推动商业化,同时借助已经建立的企业服务的良好口碑来提高定价。预计到2025年,Anthropic的年经常性收入(ARR)将突破300亿美元,首次超过OpenAI同期的250亿美元——市场显然在用实际的收益来认可这种策略。
那么,这两条道路到底哪条更好呢?其实这个问题有点偏离了重点。更准确地说,这两种路径各自在其目标市场中都找到了适合的需求点。
不过,这两条路也各自面临着真实的风险。
智谱的开源路径存在的隐患是:虽然开源能够赢得口碑,但并不一定能获得市场的定价权。 MIT协议允许任何人免费使用其模型权重,智谱的盈利主要依赖于服务层面的API和Agent。在一个主要竞争对手将Token价格压至国际竞品十分之一的市场环境中,智谱提高价格的空间自然受到限制。此外,GLM-5.1的全链路训练深度依赖于华为的昇腾910B,这就带来了供应链集中化的风险。虽然壁仞科技和海光DCU等厂商已经完成了初步适配,但“适配完成”与“实际好用”之间还有一道坎需要跨越。
至于Anthropic的闭源模式,它的隐患在于:安全约束和实用能力之间的矛盾正在显露。 最近,Claude Code遭遇了“思考深度骤降67%”的争议——AMD的AI总监Stella Laurenzo基于6852条会话日志指控其思考深度骤降,这暴露出安全保护措施对模型能力的实质性影响。闭源模式的代价是,用户在每次体验中都能感受到你为安全付出的代价。
提价是信号,但盈利的拐点依然遥远
3月31日,智谱发布了上市后的第一份年报,数据看起来很矛盾。
从积极的角度看:预计到2025年,收入将达到7.24亿元,同比增长132%,在国内独立大模型厂商中名列第一。API收入激增292.6%,Agent收入也增长了248.8%,MaaS平台的年度经常性收入达到17亿元,同比暴涨60倍,转型方向清晰可见。
然而,从消极的角度看:净亏损扩大至47.18亿元,毛利率从56.3%降至41.0%,研发开支31.80亿元是收入的4.4倍,四年累计亏损约85亿元。以约4100亿港元的市值计算,市销率接近500倍——市场似乎完全是在为未来定价,而不是现在。对比一下,腾讯的市销率大约是5倍。
在年报发布后的第二天,CEO张鹏在业绩会上明确提到要以Anthropic为标杆,原话是“当模型足够强大时,API本身就是最好的商业模式”。当天,股价大涨31.94%。市场似乎接受了这个新故事。
不过,想要成为“中国版Anthropic”,我们必须面对一个不容忽视的数字差距。
Anthropic的年经常性收入是智谱全年总收入的约285倍。它有超过千家的年消费超过百万美元的企业客户,这些客户构成了Anthropic的收入基础——每一家背后都有真实的合同和工程师使用量以及续签率。而智谱目前的MaaS ARR为17亿元,折合约2.3亿美元,与Anthropic的规模差距显而易见,说明“对标”和“追赶”之间还有很长的路要走。
更值得一提的是,GLM-5.1发布当天,智谱逆势上调了API价格10%,这是今年内的第三次提价——到2026年第一季度,Token价格累计上调了83%,但调用量却增长了400%。这组数据传递了一个有力的商业信号:用户对价格的敏感度并没有想象中那么高,似乎对能力溢价还是有一定的接受度。
不过,提价的可持续性取决于三个假设,而每个假设都充满不确定性:
- 能力溢价能否持续? 领先优势主要集中在编程领域,对于非编程场景的支持并不明显。
- 成本能否降低? 41%的毛利率显示盈利的拐点依然遥远。
- 增速能否保持? 7.24亿元的基础上,维持130%以上的增速将变得更加困难。
调价后,GLM-5.1在Coding场景下的Token价格已经接近Claude Sonnet 4.6的水平——注意,是Sonnet,而不是Opus。Claude Opus 4.6的API定价依然明显高于智谱。对于企业用户来说,同样的价格,他们面临的是“生态更成熟的Claude”与“性能接近但确定性存疑的GLM-5.1”之间的选择。
从“追赶”进入“攻坚”阶段
回到最初的问题:为什么这么多企业急于宣布接入GLM-5.1?
部分原因是这个模型确实值得尝试,尤其是在编程自动化的场景;还有部分原因是MIT开源协议提供了低成本的接入理由;更坦率地说,还有一部分是习惯使然。
但通过企业接入潮可以看到的不仅仅是一款模型的发布:中国的大模型行业正在从粗放的“追赶期”转向更加精细的“攻坚期”。
追赶期的标志是,国产模型在关键基准上与全球顶尖水平的差距从“代际差”缩小到了“个位数差”——这一点,GLM-5.1在编程领域已经做到了。
而攻坚期的挑战是,技术领先能否转化为商业壁垒,开源的信任能否转化为定价能力,以及巨额的研发投入何时能在利润表上显现出正向的印记。这三个问题,智谱还没有答案,而整个国产大模型行业也尚未找到解决方案。
GLM-5.1的发布证明了中国大模型在某些领域已经可以与全球顶尖产品一较高下。但“同台竞技”和“赢得市场”之间,依然是一段没有路标的旅程。(本文首发钛媒体APP,作者 | 硅谷Tech_news,编辑 | 焦燕)
想了解更多精彩内容,欢迎关注钛媒体的微信号(ID:taimeiti)或下载钛媒体App!








这次AI领域的快速发展,是否意味着我们要重新审视现有的教育和人才培养体系?
我觉得这个趋势下,个人开发者会有机会吗?还是大企业更有优势?
GLM-5.1的进步太惊人了,感觉中国的AI真的在崛起!
建议关注一下GLM-5.1在具体应用中的表现,特别是对中小企业的影响。
使用GLM-5.1时,建议多关注其安全性和伦理问题,确保合规使用。
有没有人觉得GLM-5.1的名字起得有点随便?
GLM-5.1的技术进步非常吸引人,为什么这么多企业都争相接入?
接入GLM-5.1的企业这么多,竞争压力不小,大家要小心选对方向。
GLM-5.1吸引了这么多企业,看来大家都对它的潜力很看好呀,未来会怎样呢?
感觉GLM-5.1真是个好东西,能帮助很多企业提升效率。