一. cursor与augment code的比较
| cursor | augment code | |
|---|---|---|
| 核心定位 | 独立的AI代码编辑器 | AI代码插件(深度集成JetBrains全家桶(IntelliJ, PyCharm等)和VS Code) |
| 代码补全 | 支持 | 支持 |
| agen模式 | 支持 | 支持 |
| mcp工具 | 支持 | 支持 |
| 远程代理 | 支持 | 支持 |
| 模型选择 | 支持自选gpt/claude/gemini | 不支持自选,据官方说,最新版用的是claude 4 sonnet |
| 是否支持规划 | 不支持 | 支持 |
| 独立的上下文引擎 | 未知 | 支持 |
| 价格 | 每月20刀的pro版 | 每月50刀的developer版 |
通过这段比较,大家可以看到,augment code其实是专门对标cursor的,功能上几乎一致,但还是有些不同之处。
首先,augment code最大的亮点之一就是它作为插件形式存在,而不是一个独立的IDE。大多数开发者都有自己习惯的IDE,就像是每个人都有自己喜欢的工具,切换IDE的时候总会有不适应的感觉。所以,augment code的无侵入设计让开发者可以通过插件轻松使用AI来提升效率,这真的是个大优势。
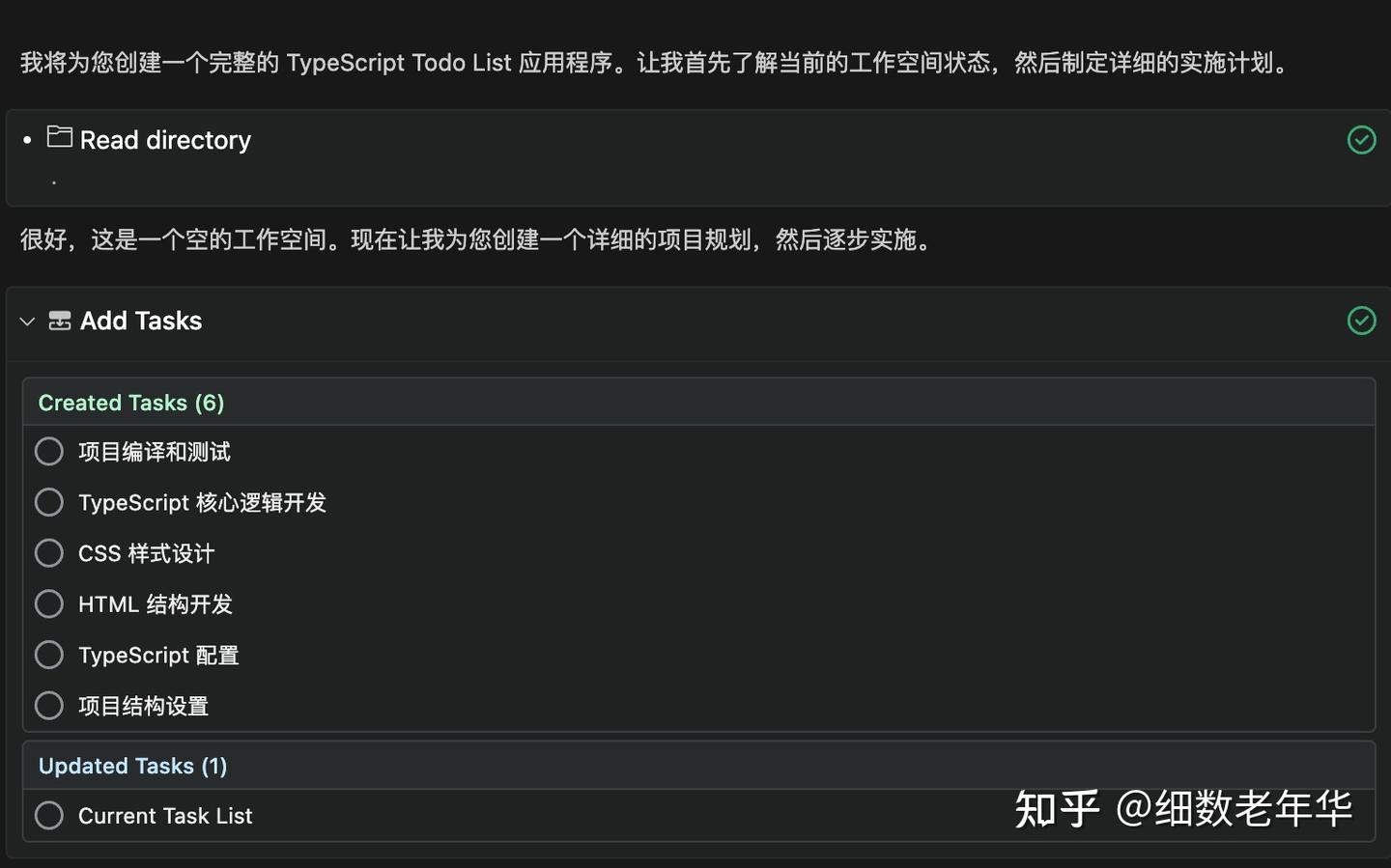
其次,planning模式也是两者之间的一个差异。其实这并不是augment code的独特卖点,很多用户可能也没怎么用过。让我给你演示一下,假设你要写一个todoList,cursor会一步一步地执行任务,而augment code则会将任务拆分成多个小任务,逐个处理。如果你觉得这些小任务不符合你的预期,还可以进行调整,添加或修改任务。不过,这种情况一般是在复杂任务时才会触发,使用下来整体体验还是不错的。
第三个差异点也是我认为augment code的一大优势,它的上下文引擎。augment memories在每轮对话后会通过remember工具来维护本地的记忆,这样的好处是,它可以做总结,即使经过多轮对话,augment code依然能记住用户的一些核心需求,减少了因为记忆丢失造成的混乱情况。
而cursor似乎在这方面没有特别的处理,从工具中可以看出。
工具对比:
| cursor | augment code |
|---|---|
| read_file – 读取文件内容(支持指定行范围) | view – 查看文件或目录内容,支持正则搜索 |
| list_dir – 列出目录内容 | str-replace-editor – 编辑现有文件(字符串替换) |
| edit_file – 编辑现有文件或创建新文件 | save-file – 创建新文件 |
| delete_file – 删除文件 | remove-files – 删除文件 |
| file_search – 模糊文件名搜索 | codebase-retrieval – 使用Augment的上下文引擎搜索代码库 |
| grep_search – 基于正则表达式的精确文本搜索 | diagnostics – 获取IDE中的错误和警告信息 |
| run_terminal_cmd – 执行终端命令(如npm install、git操作等) | launch-process – 启动shell命令或进程 |
| codebase_search – 语义搜索代码库中的相关代码片段 | read-process – 读取进程输出 |
| web_search – 搜索网络信息(需要启用) | write-process – 向进程写入输入 |
| kill-process – 终止进程 | |
| list-processes – 列出所有进程 | |
| read-terminal – 读取VSCode终端输出 | |
| web-search – 搜索网页信息 | |
| web-fetch – 获取网页内容并转换为Markdown | |
| open-browser – 在浏览器中打开URL | |
| remember – 保存长期记忆 | |
| render-mermaid – 渲染Mermaid图表 |
从功能调用来看,cursor似乎没有针对记忆进行特殊处理的功能调用,不过也不排除cursor可能通过其他方式实现这一点。总体来看,在复杂项目开发中,特别是后端项目,augment code的体验确实比cursor更智能。但是,至于这个体验差距是否值得每月多花30刀,这就看个人的选择了。
二.后端开发中augment code的最佳实践
后端开发和前端项目有些不同,对于一个中型项目来说,前端服务可能不多,但现在微服务的思想盛行,一个前端项目往往对应好几个后端项目。这就导致在AI完成项目时,可能会出现致命的问题,AI可能会把一些不属于这个服务的代码写进去,这可真让人头疼。那么,基于augment code的后端开发实践是怎样的呢?我经过几轮需求迭代,整理出了一套流程,分享给大家。
一. 画清边界,定职责
首先,让augment code阅读每个微服务的项目代码,概括出这个项目的职责范围。
然后把结果以md的形式归档在项目中,要求结构清晰,不要冗长,边界明确,方便AI理解。
完成这个步骤后,我们就得到了每个微服务的项目边界文档。
接下来可以将这些边界文档合并,最终得到后端每个微服务的职责划分。
二. 拆分需求,制定设计
作为开发者,我们的核心参考文档是来自产品的PRD,通常我们能比较容易地获取到PDF格式的PRD文档。我们可以把PRD发给Gemini或者GPT,让它转换成md格式的文档,然后将PRD文档归档到项目中。
接着,可以基于prd.md和职责划分.md,让大模型对本微服务中的任务进行功能点划分,并完成详细设计。这就生成了我们的第三份文档。
这份文档是必须重点审核的,因为它直接关系到augment code能否顺利完成任务。我们可以通过对话或手动调整其中的细节。
三. 按照任务完成编码
对于大模型来说,一旦任务明确,编码就是最简单的部分。在完成第二步后,我们可以基于task.md进行提问,使用agent模式,让它根据task.md完成需求。不过,过程中要强调几点:
1. 尽量复用项目中已有的方法和模型,避免创建冗余的东西。
2. 严格按照task.md来实现,别引入无关的技术栈和依赖。
各位读者可以参考这种模式,让augment code帮助你完成独立的需求,相信我,结果会让你惊喜。
最后小贴士:augment code有免费的社区计划,但每月只有50条消息的额度,基本上只能用几天。而且免费模式下,AI会训练你的代码,因此对于一些敏感的项目,不建议使用augment code的社区模式进行开发。