代码地址:
https://github.com/RLinf/RLinf
项目链接:
https://rlinf.readthedocs.io/zh-cn/latest/rst_source/examples/coding_online_rl.html
使用文档链接:
https://rlinf.readthedocs.io/en/latest/rst_source/examples/coding_online_rl.html
01
前言:浅谈在线强化学习技术
随着大型模型能力的不断提升,许多智能体已经突破了“可用60分”的标准,但我们仍然需要努力将它们的表现提升到80分甚至更高,真正让它们在各种场景中大显身手。强化学习的奠基人Sutton曾预言,更高的智能将会从智能体的经验中自然涌现。我们非常赞同这一观点,强化学习是推动智能体能力跃升的重要技术路径。而在线强化学习的独特价值在于它能够在实际生产环境中不断自我进化,成为智能体能力提升的利器。
最近,Cursor推出的Tab模型就是在线强化学习有效性的一个好例子。这个模型把用户每一次的互动(比如接受或拒绝建议)都视作强化信号,直接用于模型的在线优化。每天处理超过4亿次请求的真实反馈,使得模型能够高频率地进行学习和改进,最终建议的接受率提高了28%。这为我们在智能体优化中引入在线强化学习提供了重要的参考。
与此同时,随着越来越多的智能体服务进入实际应用阶段,如何高效且低成本地为已上线的系统引入在线强化学习能力,已成为亟待解决的问题。我们认为,在线强化学习的训练不应该和智能体系统紧密耦合并持续运行,而是应以模块化的形式与智能体系统解耦,并由智能体系统按需调用。这样可以实现系统的模块化设计,让智能体服务组件和在线强化学习模块在功能上互不干扰,各自独立优化,而不增加整体系统的复杂性。比如,在线数据清洗可以完全在在线强化学习模块中进行,而不影响智能体服务。当在线强化学习将模型优化到理想状态时,可以暂停训练,并将优化后的模型部署到所有线上环境。如果未来出现新的调整需求,比如用户偏好变化或者工作流程更新,智能体系统可以再次激活在线强化学习模块,开始新一轮的训练。因此,制定智能体系统与在线强化学习之间的标准化交互接口,使其成为智能体系统的“可选项”甚至“标配能力”,将是推动技术普及的关键。
此外,如何通过在线强化学习来实现智能体服务的降本增效也是一个重要话题。面对用户数量增加带来的成本压力,厂商往往希望用小模型替代大模型,但又要确保效果不下降。我们认为,通过在线强化学习,可以让小模型在特定场景下的能力追赶甚至超过大模型。具体来说,可以通过分流部分用户请求,对一个已经经过离线SFT或强化学习的小模型进行在线强化训练,一旦效果达标,就可以全量替换;如果未达标,则可以提升模型规模继续实验。这样就能实现一种用小模型替代大模型的成本可控的智能体优化路径,在某些场景下能够实现超过10倍的成本下降。
02
从思考到实践:RLinf-Online及其实现路径详解
基于上述思考,我们最近推出了第一个开源的智能体在线强化学习框架RLinf-Online。这个框架基于大规模强化学习框架RLinf,复现了Cursor的在线强化学习方案,验证了在线强化学习在提升模型代码补全能力方面的有效性。更重要的是,它支持以组件的形式轻松接入已部署的智能体服务,实现智能体的持续自我优化和成本效益提升。我们将其全面开源,希望能帮助更多的智能体优化和应用落地。
「RLinf是今年9月份,由无问芯穹联合清华大学和北京中关村学院共同打造并开源的大规模强化学习框架。这一灵活、高效、可扩展的框架不仅适用于多种具身强化学习场景,也适合推理任务中的强化学习应用,甚至可以用于构建各种智能体。」
具体来说,我们采用Continue作为代码编辑器的端,用户可以直接在VSCode中安装Continue插件(https://github.com/RLinf/continue)进行开发;而RLinf则作为后端系统,负责大模型的服务和在线强化学习的训练。值得注意的是,大模型的服务后端也可以替换为已经部署的智能体服务,而RLinf则可以灵活地作为提供在线强化学习能力的通用组件接入系统。接下来,我们将详细介绍这一成果背后的技术路径和实现过程。
- 前情提要
代码补全功能简介
对于像Cursor这样的智能编程编辑器,代码补全是它的核心功能之一。通常情况下,当光标停留在某个位置时,编程助手会根据上下文给出插入内容的建议。实现这个功能的常用方法是FIM(Fill-In-the-Middle)任务:模型会接收光标位置的上下文,然后预测中间需要填充的内容。目前,大多数大语言模型(LLM)在预训练阶段已经针对FIM任务进行了优化,只需按以下格式组织输入:
上文下文
模型就能生成合理的中间补全内容。这种设计使得LLM能够自然而然地适应编辑器中的代码补全场景。
Continue插件的代码补全逻辑
在我们的实验中,我们基于开源AI编程IDE Continue实现了完整的在线强化学习(Online RL)代码补全案例。
Continue默认支持基于FIM格式的补全任务,但原生版本不具备人类反馈(Human Feedback)上报的功能。
为此,我们对插件进行了轻量化的改造:
- 当用户按下Tab键接受补全建议时,插件上报accepted=True;
- 当用户在10秒内未按下Tab或进行了其他编辑操作时,上报accepted=False。
通过这种方式,我们能够直接从真实用户的互动中获得强化信号(reward),而不需要额外训练一个reward模型来拟合人类偏好,从而实现了从人类到模型的直接强化学习闭环。
2. 系统搭建
流程概览
整个在线强化学习的流程可以概括为三个核心步骤:
(1)交互与反馈采集:
编码智能体向用户提供代码补全建议,用户的“接受”或“拒绝”操作构成明确的强化信号。
(2)即时在线更新:
用户的反馈被传送到RLinf的后端系统,用于训练生成模型,模型会基于On-policy策略实时更新,并同步回线上智能体,以获取新的交互反馈。
(3)效果验证与部署:
在线训练结束后,通过A/B测试评估新模型的接受率是否优于原模型;如果效果提升,就统一部署到线上环境。
RLinf-Online搭建
接下来介绍如何基于RLinf快速搭建这个流程:
(1)RLinf Worker抽象
RLinf框架提供了Worker的编程接口,这是构建整个框架的基础组件。Worker表示一个可执行的组件,大的组件可能是推理实例、训练框架,而小的组件则可能是数据加载器等。通过继承Worker类,可以将具体的执行组件进行抽象,并提供与其他Worker交互,以及被RLinf调度、分配和管理的能力。
(2)RLinf Channel通信
RLinf框架也提供了高性能、易用的异步通信抽象Channel,能够自适应使用优化过的点对点后端(如CUDA IPC和NCCL),并封装为生产者-消费者队列的通信模式。因此,Worker1 -> Worker2的通信可以这样实现:
self.comm_channel = Channel.create("Comm") #创建一个 channel
Handle1 = self.worker1.rollout(
output_channel=self.comm_channel,
) # 执行数据生成
Handle2 = self.worker2.run_inference(
input_channel=self.comm_channel,
)# 执行inference流程仅需三行代码就可以实现Worker1 -> Worker2的通信逻辑,极大简化了代码结构。
(3)基于RLinf构建在线强化学习训练流程
有了Worker和Channel这两个基本组件,我们就可以搭建完整的在线强化学习训练流程。整体系统架构如下图所示。
在线强化学习的探索与展望
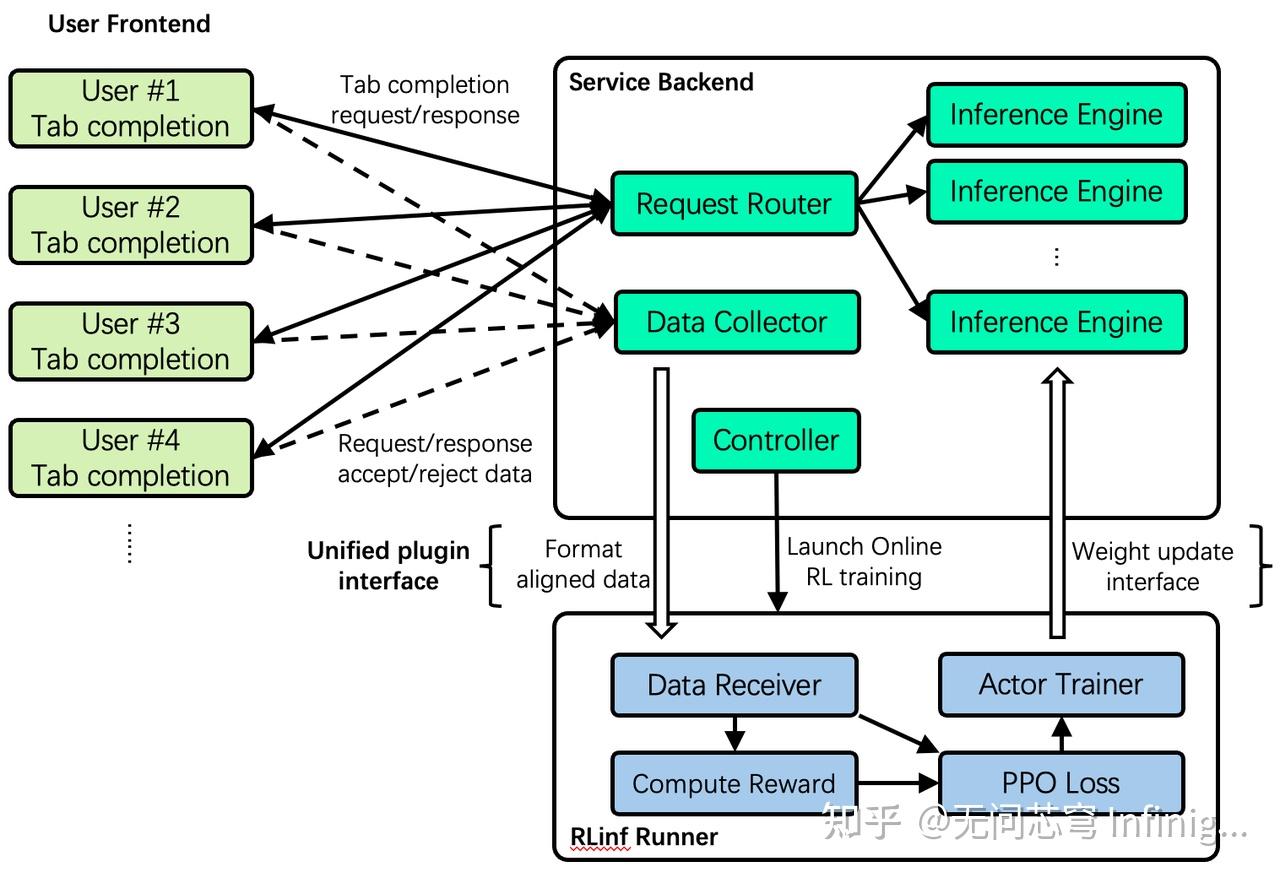
想象一下,我们的代码补全代理已经作为一个完整的在线服务上线了,它由用户前端(User Frontend)和服务后端(Service Backend)这两部分组成。为了让这个系统具备在线强化学习的能力,我们在它的插件层面引入了一个新的组件——RLinf Runner。跟那些长期运行的后台服务不一样,RLinf Runner 是一个轻量级的模块,它不是常驻的,而是可以根据需要由线上系统的控制器(Controller)调用。我们为 RLinf Runner 设计了一套与在线代理交互的接口,主要用于以下几个方面:
- 获取在线数据,比如请求(request)、响应(response)内容,以及用户的反馈(接受或拒绝);
- 接收并更新模型的权重,这样就能实现对代理策略的实时优化。
在 RLinf Runner 的内部,我们将整个强化学习的过程拆分成三个核心的工作组件:
- 数据接收器(Data Receiver):负责获取并缓存线上系统的交互数据;
- 奖励计算器(Compute Reward):依据用户反馈来计算即时奖励信号;
- PPO 损失 + 策略训练器(PPO Loss + Actor Trainer):执行策略优化和模型更新。
这些工作组件之间的通信依靠RLinf Channel来实现,这是一种高效的异步数据传递机制,让整个在线训练流程可以持续进行。当服务后端的控制器启动 RLinf Runner 后,在线强化学习的过程就会自动展开:系统接收线上服务的数据、计算奖励、更新策略模型,并将改进后的模型权重实时返回给服务后端。为了确保在线服务的稳定性,在线强化学习可以先在一些愿意参与新模型实验的用户中进行测试。
如果想了解更详细的系统部署和测试信息,可以参考中文版文档https://rlinf.readthedocs.io/zh-cn/latest/rst_source/examples/coding_online_rl.html或英文版文档https://rlinf.readthedocs.io/en/latest/rst_source/examples/coding_online_rl.html。
3. 算法设计
除了系统设计上的模块化,我们在在线强化学习(Online RL)算法的设计上也进行了深入的研究。在 Online RL 的场景中,每个请求(request)通常只会对应一次响应和一次用户反馈(接受或拒绝),因此GRPO算法就不再适用,因为它需要对同一输入进行多样化的响应组来计算相对偏好。于是,我们采用了改进后的PPO算法,主要的调整是去掉了 critic 模型,优势估计(advantage estimation)简化为蒙特卡洛回报(Monte Carlo return)的简版(仅依赖当前的奖励)。虽然这种方法可能会带来较大的训练方差,但借助 PPO 的clip机制,我们能够有效限制策略的更新幅度,防止训练过程中的崩溃,从而实现一种高效且稳定的简化策略。在代码补全的在线强化学习训练过程中,奖励来自于用户的反馈信号(也就是用户的接受或拒绝操作)。
因为目前缺乏足够规模的真实在线使用场景,我们采用了LLM 模拟用户评分(LLM-as-a-Judge)的方式,对模型生成的补全结果进行打分。具体来说,我们使用 LLM(DeepSeek-V3.1)对生成的补全结果进行0到10分的评分,平均得分则作为模型在测试集上的综合表现指标。
4. 性能一览
训练配置
数据集构建
我们选择了 code-fim-v2 数据集,这个数据集包含多种编程语言的代码补全示例。从中我们筛选出 Python 的样本,并进一步过滤掉那些补全内容过短的样本,最后保留了大约4000条高质量数据。其中3000条用于训练,1000条用于测试。每个样本包括上下文(prefix)与下文(suffix)的代码片段,模型需要根据这些上下文生成中间的补全内容。
主要参数
实验的基模型是Qwen2.5-Coder-1.5B。由于没有加入 KL 正则化,过高的学习率可能导致模型遗忘原有分布,因此我们选择了较低的学习率(2e-6)以保证稳定收敛。同时,采用 bf16 的训练精度,相较于 fp16 在训练初期的梯度范数更加稳定。
此外,为了快速验证强化学习在这个任务上的有效性,我们还采用了GRPO(组大小 = 8)进行离线训练的对比实验,以评估不同训练方式下模型在代码补全任务上的性能变化。
实验结果
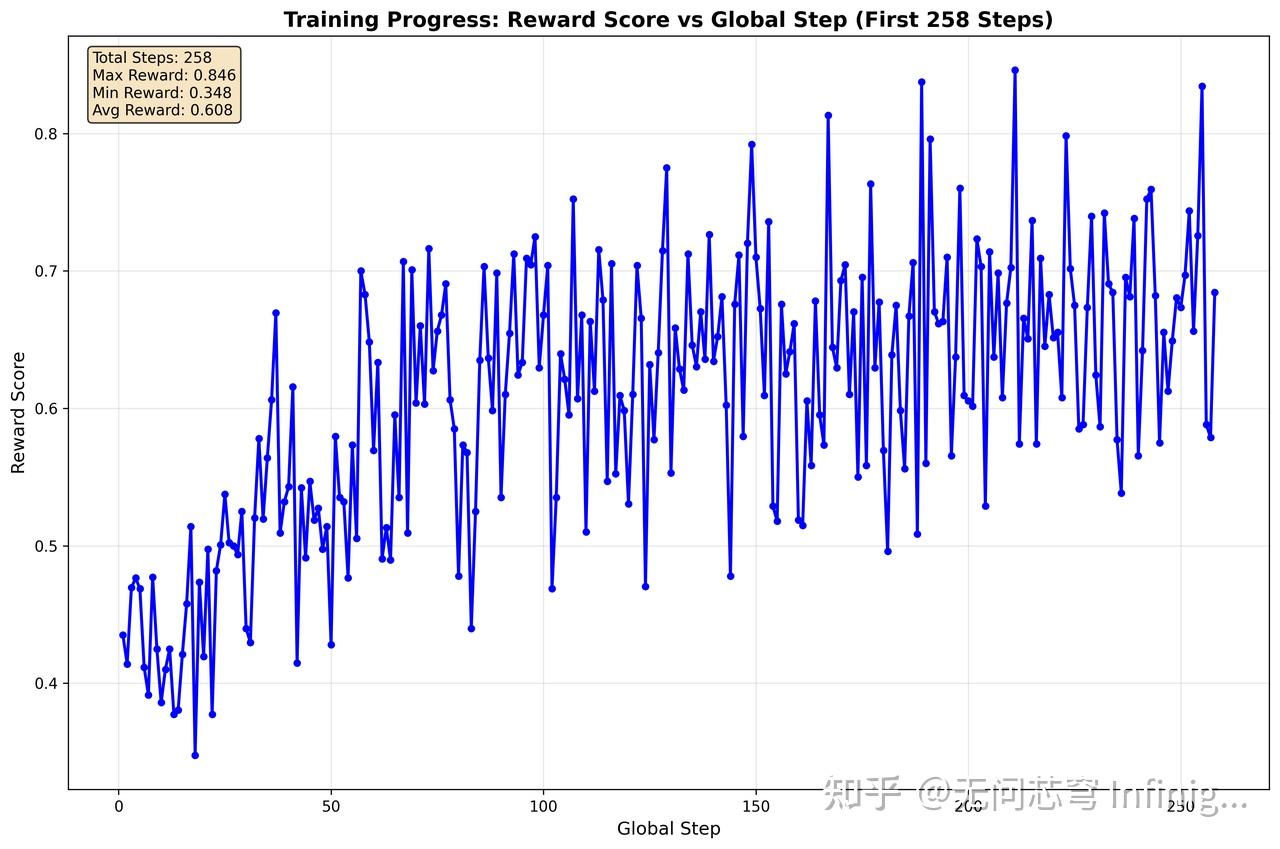
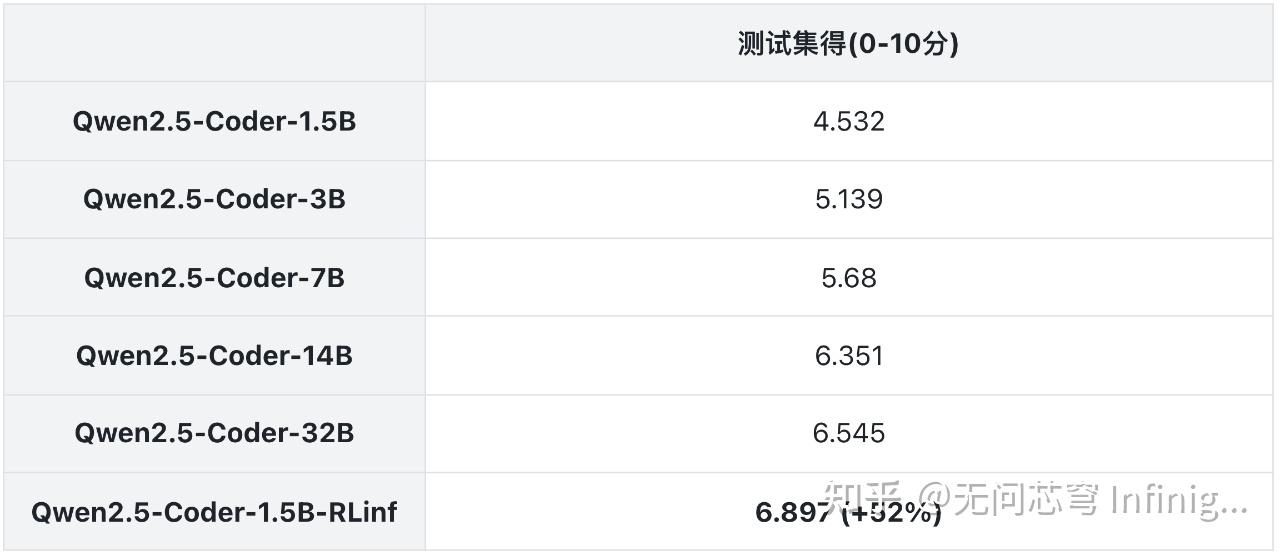
如图1所示,强化学习确实让模型的性能不断提升。测试集的结果如表1所示,Qwen2.5-Coder-1.5B-RLinf 在测试集上显著提升了(4.532 -> 6.897),涨幅超过了50%,甚至超越了同系列的32B模型。这说明在线强化学习可以有效提升模型的部署性能,而且小模型同样有着巨大的潜力。
03
未来展望
在线强化学习为代理的持续进化指明了方向,但系统性挑战依然存在,包括如何高效清洗和处理在线数据、在模型动态更新中保障性能的稳定性,以及如何在多样化的用户偏好中实现个性化策略优化等关键问题。这些不仅是系统与算法上的思考,更是智能体落地时亟需解决的根本性难题。尽管如此,我们相信,随着智能体应用生态的逐步成熟以及相关技术的不断突破,这些挑战终将逐步克服。智能体也将因此实现从“从经验中学习”到“在交互中涌现”的根本性跨越。
RLinf-Online 是我们团队在智能体在线优化方案上的初步探索与实践,当前版本仅以人类代理的形式进行性能模拟,但结果已经清晰展现出在线强化学习的无限潜力。目前我们正在将这一流程上线到生产环境,并在实际业务中进行测试。同时也期待与更多的开发者、团队和合作伙伴展开深入合作,共同拓展大模型时代下强化学习的应用边界,赋能更智能、更高效的代理未来。