四个月前,GPT-5 发布的时候,大家对它的评分虽然很高,但聊天的感觉却有点冰冷。到了一个月前,GPT-5.1 试图回应这些负面评价,强调“更好聊天、更易交流”,终于让它的人情味回归了。
可没过多久,Google 的 Gemini 3 就突然冒了出来,直接把 LMArena 的排行榜给刷了个遍。紧接着,Anthropic 的 Claude Opus 4.5 也上线了,在编程领域将 OpenAI 按在地上摩擦。
就在这种情况下,昨天凌晨 GPT-5.2 终于发布了。
这次发布的背景其实挺有意思的,几天前,媒体还爆料 Sam Altman 发了一封 Code Red 的内部邮件,要求全公司集中力量来改进 ChatGPT。虽然官方表示 GPT‑5.2 并不是专门为了应对 Gemini 3 而推出的,但从 Code Red 和发布的时间来看,Gemini 3 明显加速了 OpenAI 推出这一版本的步伐。
这回,尽管 OpenAI 还是提到 GPT-5.2 在跑分上比 5.1 有所提升,但他们更想强调的是一个关键词:专业知识工作。
换句话说,这次的目标不是“聊得更好”,而是“干活更出色”。
第一个能在“实际工作”上与人类专家平起平坐的模型?
OpenAI 这次推出的新基准测试叫 GDPval,主要是让 AI 完成 44 种职业的实际工作,包括制作 PPT、表格和写分析报告等。
结果如下:
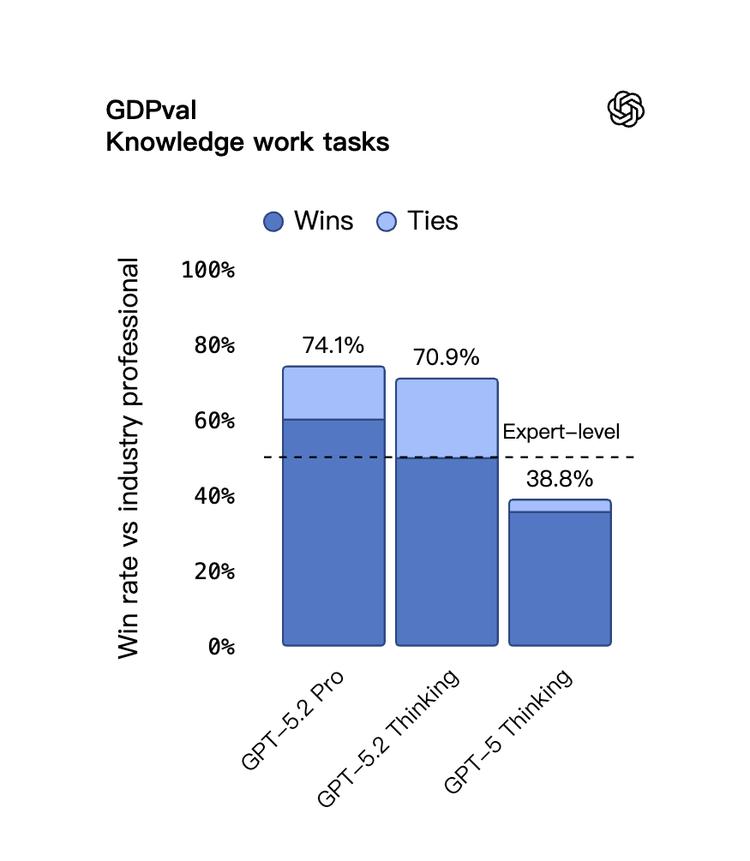
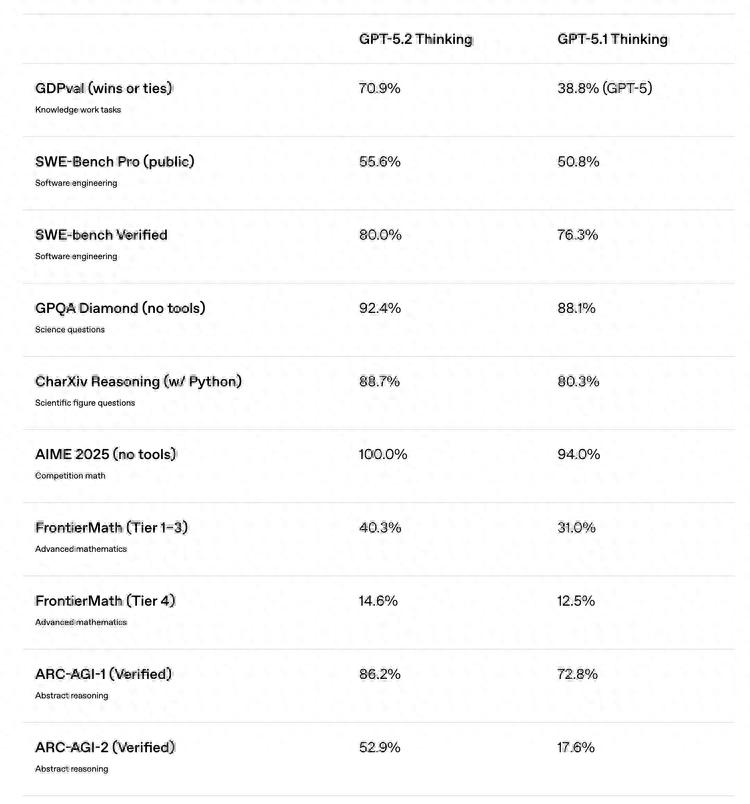
GPT-5.2 Thinking 在70.9%的任务上能够和行业专家打平甚至胜出。
而上一代的 GPT-5 仅有38.8%。
Claude Opus 4.5 的成绩是59.6%。
Gemini 3 Pro 则为53.5%。
更惊人的是它的效率:速度快11倍,成本却不到1%。
当然,GDPval 是 OpenAI 自己设定的基准,尚未经过独立验证,所以这“能平起平坐人类专家”这一说法还需谨慎。但即便打个折扣,从 38% 跳到 70%,这样的提升确实不容小觑。
最近,Anthropic 的 Claude 在类似任务上也取得了显著进步,但从 5.2 的发展方向来看,OpenAI 显然想在“AI 替代知识工作”这条赛道上抢占先机。
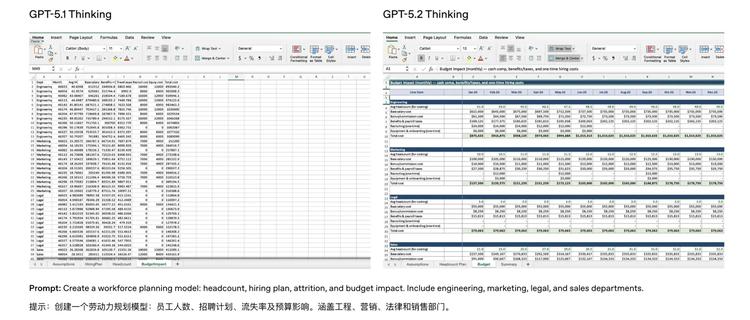
OpenAI 官方还展示了一些实际工作案例,比如让模型制作一个劳动力规划表格(包括员工人数、招聘计划、流失率和预算影响),5.1 仅仅输出了一堆原始数据,而 5.2 则会自动按部门分类,添加颜色标注,层级结构清晰,看起来就像是有人认真排版过一样。
Coding:前端又双叒叕更强了
编程能力也是 5.2 的一个重点宣传方向。
升级后的GPT-5.2:更聪明的助手,价格也涨了!
SWE-bench Pro的得分是55.6%,相比之下,5.1版本是50.8%,Gemini 3 Pro则为43.3%,而Claude Opus 4.5得分52%。
在SWE-bench Verified部分,得分达到了80%,与Claude Opus 4.5的80.9%几乎不相上下,这个数据已经到达了一个瓶颈。
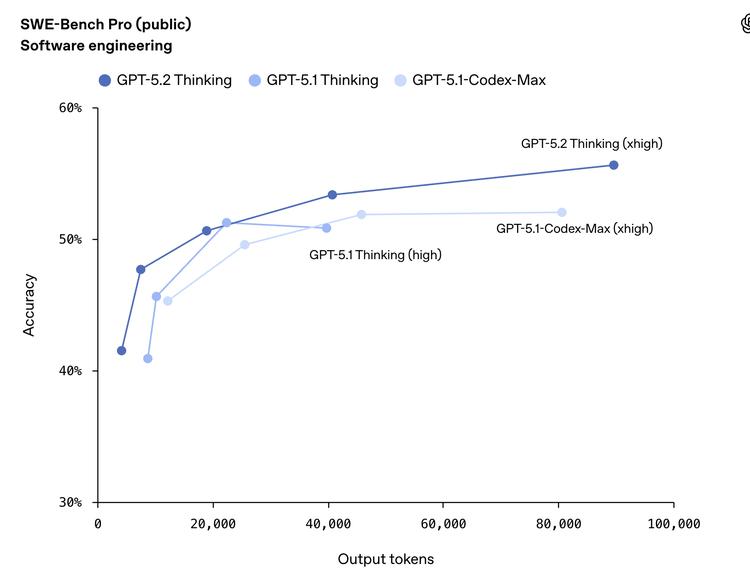
这次OpenAI主要推的是SWE-bench Pro,而不是Verified,主要是因为Pro版本在应用场景上更加丰富,干扰因素更少,能更好地反映出软件工程的真实能力。
前端开发的能力又上了一个新台阶,尤其是在3D场景渲染和复杂交互界面方面。Cognition、Warp、JetBrains、Augment Code这些合作伙伴都指出,5.2在交互式编程、代码审查和bug查找方面都有明显的进步。
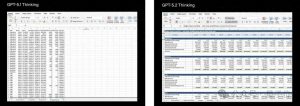
你可以通过这个波浪模拟案例的对比来直观感受一下。
GPT-5.2思考中:
Gemini 3 Pro:

更像数学家了
这次升级中,数学能力也是一个重要亮点。
来看几个重要的数据:
FrontierMath(Tier 1-3)得分40.3%,创下了新的行业纪录,而上一代的5.1仅为31%。
AIME 2025的满分是100%,这是第一个在不借助工具的情况下完成这个数学竞赛基准的模型。
在GPQA Diamond(博士级科学问答)中,Thinking版得分92.4%,Pro版则为93.2%。
不过,最让人瞩目的,是GPT-5.2 Pro在一个真实的数学研究问题上的表现。
OpenAI在博客中提到,研究者利用GPT-5.2 Pro探讨了一个统计学习理论中的开放问题,这个问题早在2019年的数学会议上就被提出。在特定的高斯设定下,模型提出了一个证明确保的思路,后来被人类研究者验证并加以扩展。
这虽然不是AI像科幻电影中那样从零开始发现物理定律的场景,但确实是AI在专家的监督下,提供了具有非凡数学洞察力的例子,并经受住了专家的审查。5.1版本没有被广泛报道能做到这一点。
有位测试者表示,5.1就像是个很棒的数学助手,而5.2则开始显露出“初级合作者”的特质,尤其是在与代码工具结合使用时。
API价格上涨:OpenAI的小心思
5.2版本的API价格有所上涨。
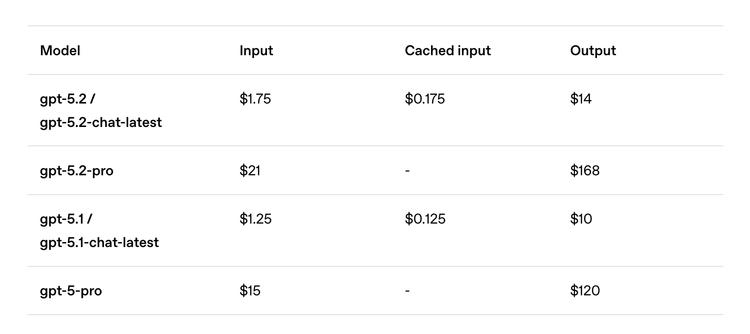
输入和输出的费用都提高了大约40%:每百万输入$1.75,每百万输出$14。而Pro版本的价格更高,分别为$21和$168。
OpenAI新版本5.2的升级亮点
官方说,虽然单价提高了,但是模型的效率也有了提升,完成同样的任务所需的token减少了,因此“在达到同样质量的情况下,整体成本可能反而更低”。
可是,如果减少的token只能保证“同样的质量”,那升级的意义又在哪里呢?如果真的是又好又省,干嘛不直接说“更好更便宜”呢?
说白了,模型的确变得更强了,但OpenAI选择把这些效率提升的好处留给自己,而不是分享给用户。
几个关键的提升
除了上述变化,5.2版本还有一些实打实的提升:
错误率降低30%
这一点可真是个大进步。很多人只关注“智能”,但实际使用中会发现,国产模型和国际顶尖模型之间,在幻觉控制的能力上,差距往往比纯智力的差距更让人感受到。5.2的思考版本比5.1的错误率降低了30%,在日常决策、研究和写作方面的表现会更加可靠。

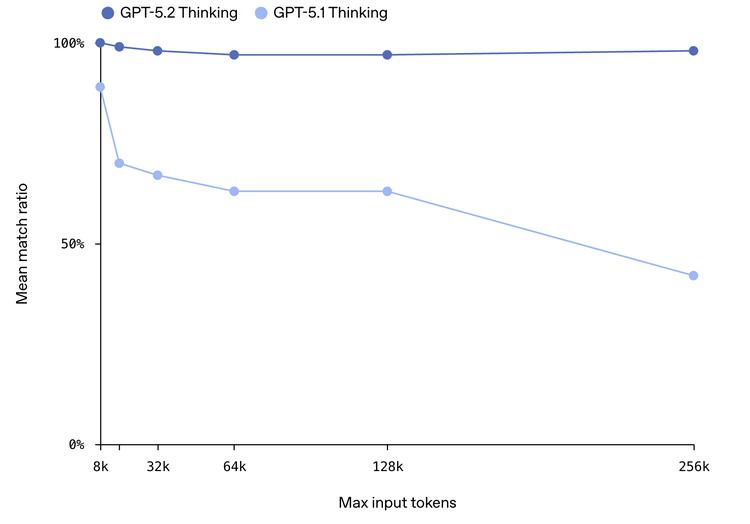
长文处理能力提升
之前处理长上下文的时候总是困难重重,内容太多模型就容易忘记。现在5.2在256k token的测试中表现得相当稳定,基本能够记住关键信息。像合同审核和文献梳理等需要反复引用上文的场景,体验会好很多。Box的反馈显示,5.2在长文档信息提取的速度上提升了40%,推理的准确性也提高了40%。
图像理解能力
在图表理解和软件界面识别方面,错误率减少了一半。在CharXiv Reasoning(科学论文图表理解基准)测试中,5.2的思考版本达到了88.7%,比5.1有超过8个百分点的提升。
GPT-5.2:升级与期待之间的微妙平衡

在OpenAI的内部测试中,有人给模型看了一张模糊的主板照片,惊人的是,它竟然能准确识别出那些关键的元件。这就意味着,如果你把一张模糊的业务报表截图扔给AI,它很可能能直接把里面的数据整理出来,这对从事数据分析的人来说,简直是个福音!毕竟现在不少海外用户已经开始依赖AI作为他们的数据分析助手了。

Code Red下的应对之策
从远处看,GPT-5.2其实是一次“补课”的过程。
自8月发布的5.0,到11月的5.1,再到12月的5.2,这短短四个月内的三个版本,说明了OpenAI面临的压力,尤其是Gemini 3和Claude Opus 4.5的竞争。结果是,PT-5.2在各大基准测试中重新夺回了一席之地,但更重要的是,它在处理长时间知识工作、复杂编码和代理工作流方面的表现尤为突出。
另外,有些人认为这种紧急响应和小步快跑的策略可能会变成常态,年底时各大公司可能还有新产品发布。这样做的好处是,实验室们会被迫加快模型的开发,使其更经济实惠,更具商业价值;但坏处是,大家过于专注短期的基准测试,可能会忽视那些需要长期投入的基础性创新。
社区的反馈也相当多样,认真工作的用户普遍觉得这次升级很不错,长上下文和复杂推理的能力确实更稳定了;但那些喜欢和AI聊天的用户则表示“5.2变得冷冰冰的,像是从好友变成了HR”,人情味少了不少,还有人抱怨说期待已久的成人模式依旧遥遥无期。
总结一下,如果你是ChatGPT Pro的用户,5.2在需要深入分析和复杂推理的场景下,绝对值得尝试——比如制作PPT、表格、报告,或者处理长文档,这方面的进步是实实在在的。
不过,如果你期待的是日常聊天体验的质变,可能会感到失望。5.2的真正价值,可能要等到它与Codex这样的代理产品结合,真正为你省心的时候,才能完全释放出来。
最终,名次并不重要,能否真正解决问题才是关键。这一点,OpenAI似乎已经领悟到了。