
最近,Vibe coding可真是热得不行,但你知道吗,刚刚有位大佬搞定了当下流行的AI编程神器Cursor和Windsurf背后的算法原理!
今天凌晨,技术大神Nir Diamant发了一篇超棒的文章,深入剖析了Cursor和Windsurf的核心算法。就像你玩抖音时得了解推荐算法一样,我们现在用Vibe Coding,也得搞清楚怎么跟这些编程助手对话,了解它们的思维方式。这些细节,真心值得大家好好收藏和研究。

现在市场上有一大堆AI编程工具,各种Copilot层出不穷,但能真正让开发者会心一笑的,非Cursor和Windsurf莫属。这两者的魅力,除了能帮你编码,更在于它们像个真正的合作伙伴,懂你想要做什么。
那么,这两款工具到底是怎么运作的呢?它们背后的算法和系统又是什么样的?言归正传,咱们直接来看看干货。

Cursor和Windsurf
如何理解你的代码
如果想让AI编程助手发挥真正的作用,它得理解整个代码库以及你的意图。Cursor和Windsurf都搭载了先进的上下文检索系统,使得AI能够“看懂”你的代码。
先来聊聊Cursor的做法。
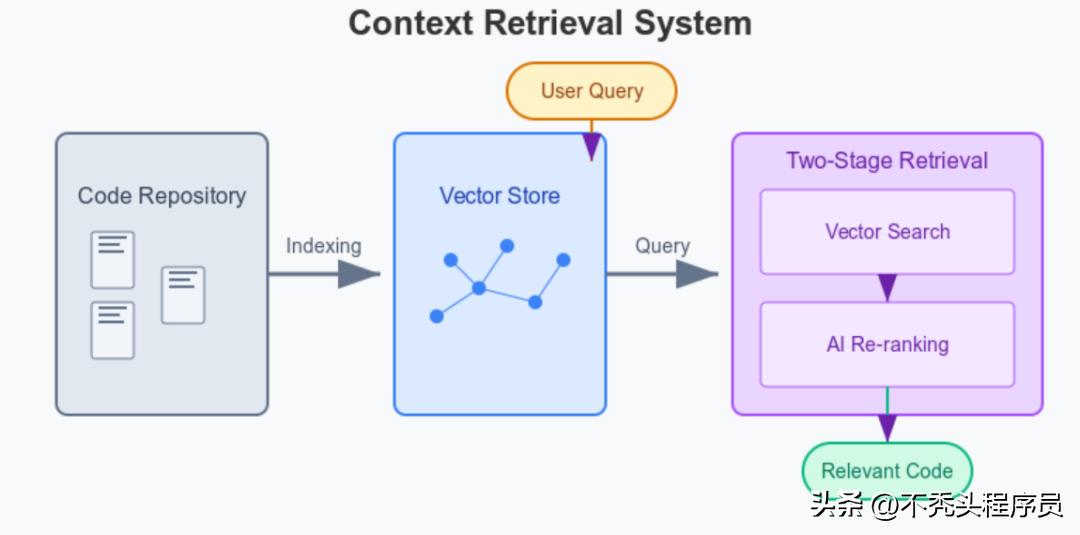
- Cursor会把整个项目索引到一个向量数据库,想象一下就像是绘制了一张智能代码地图,将语义相近的代码聚集在一起。
- 在索引的时候,它会用专用的编码器模型,尤其强调注释和文档字符串,以便更好地捕捉每个文件的功能和意图。
- 当你提问时,它会使用“两阶段检索”的方式:
### 聊聊Cursor和Windsurf的智能代码搜索
- 向量搜索可以帮你找到那些可能相关的代码片段。
- 接着,AI模型会按照相关性给这些片段重新排个序。就像图书管理员,先把所有有关某个主题的书找出来,然后再挑出最合适的给你。
值得一提的是,这种两阶段的检索方式,相比于老旧的关键词或正则搜索,效果要好得多,尤其在处理复杂的代码行为问题时更是如此。
- 你还可以用 @file 或 @folder 标签,像是对它说“帮我翻这几章”。
- 而且,当前打开的文件和光标附近的代码,会自动被纳入考虑范围。
接下来,Windsurf的做法也差不多。
- Windsurf的索引引擎会全面扫描代码库,建立一张可供搜索的代码地图。
- 它利用基于LLM的搜索工具,声称比传统的嵌入式搜索更加精准,能更好地理解你的自然语言问题并找到相关的代码。
- 在给出建议时,它不仅会考虑当前打开的文件,还会自动从整个项目中获取相关内容,实现项目级的智能感知。
- 同时,它还提供了“上下文固定”的功能,你可以把设计文档等重要信息“钉”在一个AI永远能看到的地方,AI随时都能参考这些内容。

Cursor和Windsurf
它们是怎么“思考”的
作者总结,这两款工具的“思考方式”主要是通过巧妙设计的提示和上下文管理策略来实现的。
先来看看Cursor的提示结构。
- 它采用了结构化的系统提示,带有和等标签,用来整理不同类型的信息。
- 明确告诉AI该怎么做,以便塑造它与用户的互动方式:
- 尽量避免无谓的道歉,
- 在行动前先给出解释,
- 而不是在聊天中直接给出代码,而是用专门的代码编辑器来处理。
- 它还利用了“上下文学习”的技术:在提示中展示正确的工具调用或响应格式,类似于用实例教新手。
在这方面,Windsurf的机制略有不同。Windsurf的Cascade Agent则更为综合——
- 它结合了AI规则和可持续记忆机制,形成了一种更灵活的工作方式。
### Windsurf与Cursor:智能工具如何高效协作
- Memories可以分为用户自己创建的(像API说明那样)和AI自动生成的(基于过去的互动)。这就意味着,Windsurf能够“记住”你项目的变化历程,而不是每次都得从头开始。
而且,Cursor和Windsurf有一个共同之处:它们都拥有高效的上下文窗口管理能力(也就是一次能处理的文本量),会压缩信息,并优先显示与当前任务最相关的内容。

那么,它们是怎么完成任务的呢?
Cursor和Windsurf都采用了一种叫做ReAct(推理与执行结合)的模式,把语言模型变成了多步骤的智能代理。
先说说Cursor的工作步骤吧。
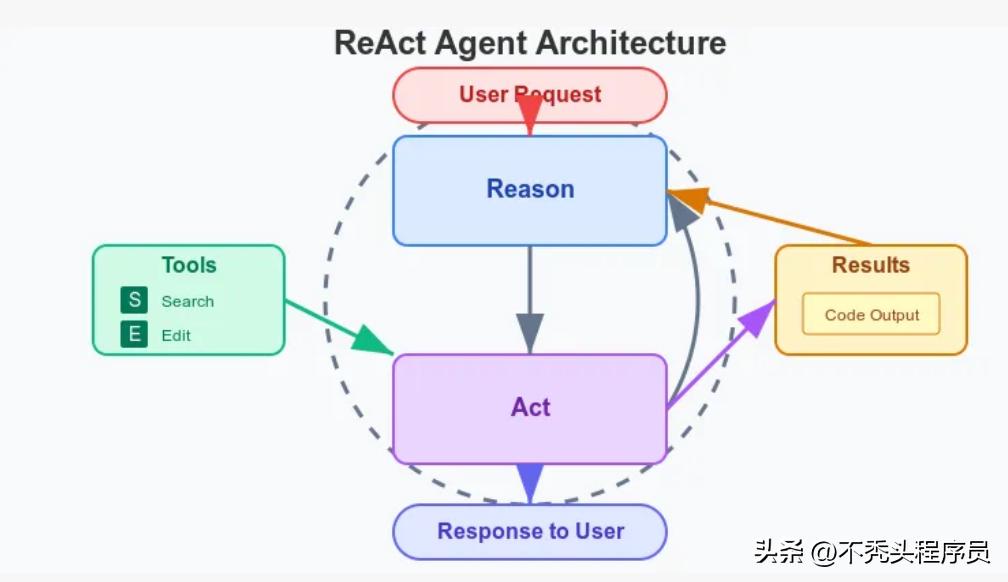
Cursor的代理以循环的方式进行工作:AI选择工具→解释意图→调用工具→查看结果→决定下一步。它能使用的工具有:代码搜索、文件读取、代码修改、执行shell命令,甚至可以在线搜索文档。
值得一提的是,Cursor在这方面进行了一个重要优化——“特种diff语法”:它不会让AI去重写整个文件,而是建议具体的“语义补丁”,然后通过一个独立且快速的模型来合并这些补丁。这样不仅效率更高,也减少了出错的可能性。
同时,Cursor会在沙盒环境中测试实验代码,确保不会对真实项目造成影响。
例如,如果你让它“修复认证Bug”,它可能先会找到相关的代码文件,接着阅读、修改它们,再运行测试看看修复是否成功。每一步都能让你清楚地知道发生了什么。而且,它会限制自我修复的循环次数(比如“不超过3次”),避免陷入死循环。
Cursor还采取了“专家混合”机制:用强大的大模型(比如GPT-4或Claude)来进行决策推理,而使用小模型来执行具体任务,就像一个高级架构师制定方案,而专业团队来具体实施。
接下来看看Windsurf。Windsurf的Cascade也有类似的机制,但更注重“AI流程”的设计。
生成计划 → 改代码 → 请求用户确认 → 运行代码 → 分析结果 → 提出修复。
当你发出请求时,Cascade会生成一个执行计划,进行代码修改,征求你的确认,然后才会运行代码。如果你同意,它还能在集成的AI终端中运行代码,分析结果并提出修复建议。
更厉害的是,Windsurf的代理系统很强大,最多可以在一个流程中串联多达20个工具调用,你根本不需要手动介入。这包括自然语言代码搜索、终端命令、文件编辑,以及连接外部服务的MCP协议。这样的能力让Cascade可以一次性完成复杂任务,比如安装依赖、配置项目或实现新功能。
更让人惊叹的是,如果你在AI执行过程中手动修改了代码,Cascade会立即检测到并自动调整所有相关部分,实现你和AI的实时协作。

背后的“大脑”中枢
模型架构
说实话,这两款工具都依靠了多种AI模型来处理不同的任务,力求在反应速度和输出质量之间找到一个平衡点。不过,它们的具体实现方式却各有千秋。
Cursor的模型系统是这样的:
- 它采用了“嵌入-思考-执行”的三步代理循环(Embed-Think-Do Agent Loop)。
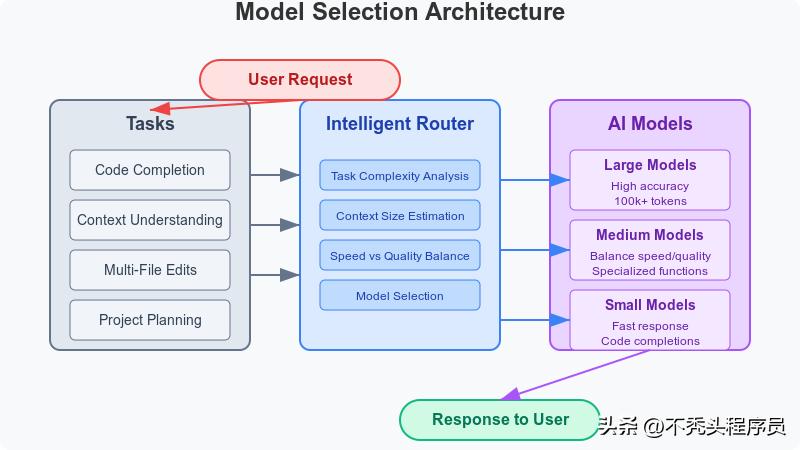
- 系统会根据任务类型来挑选最合适的模型。
- 比如,它会用100k tokens的Claude模型来处理复杂的项目上下文和推理,帮助它“看得更远”。
- 生成向量嵌入的模型与OpenAI的text-embedding-ada相似。
- 在代码补全和编辑的过程中,系统会依据任务的复杂度和用户的设置灵活选择模型。
- 其核心创新在于:通过智能动态路由机制,能够根据不同场景自动评估使用大模型还是小模型,从而优化质量和响应速度。
而Windsurf的模型策略则显得更加明确:
- 他们投入了大量资源来训练自家专用的代码模型,这个模型是基于Meta的Llama架构:
- 70B参数的基础模型适合日常任务;
- 而405B参数的高级模型则用于应对更复杂的挑战。
- 还支持用户自由选择GPT-4或Claude等外部模型,极大地提升了架构的灵活性。
- 在模型选择方面,小模型用来处理简单建议,大模型则负责多文件的重大修改,确保每个任务都能匹配到最合适的“智慧大脑”。
- 它能逐个token实时反馈,让你能直观地看到代码是如何被“写出来”的。
- 当生成的代码出现问题时,它会自动检测并尝试修复,省去你手动干预的麻烦。
- 它会跟踪你光标的位置,以便在你需要补全时给出建议,并预测你可能会修改的地方。
- 后台会持续更新向量索引,确保新写入的代码能立即被搜索到,AI对代码库的理解始终保持“新鲜感”。
- 同样支持流式输出,为你提供“沉浸式工作流程”。
- 它的Cascade代理会在你修改代码时立刻感知,并实时调整计划。
- 基于事件驱动架构,保存文件和文本修改等操作会触发AI重新推理。
- 通过SSE(Server-Sent Events)保持编辑器、终端和聊天窗口的实时同步。
- 当你运行代码遇到错误时,AI能迅速捕捉到错误信息并给出解决方案,免去你手动复制粘贴的麻烦。
它们如何与你保持同步(Sync机制)
实时同步是让编程体验流畅的关键,能迅速适应用户的操作真的是太重要了。这两种系统都有着精巧的同步机制。
首先,我们来看看Cursor的机制。它的亮点在于提供了token级别的流式响应:
接下来是Windsurf的核心理念,它更注重“工作流畅感”。
ps:这种设计让AI就像一个全神贯注的编程伙伴,时刻关注着你的代码并主动配合。
最后,值得一提的是,这些内容是作者Diamant花费了大量时间研究公开资料后对Cursor和Windsurf这两款AI工具“核心机制”的理解,当然其中的一些细节也可能会随着后续的更新而有所变化。

网友:怪不得!
终于找到了Cursor理解力差的原因
这篇文章发出后,很多网友纷纷为Diamant的努力点赞,甚至有些人表示对“大模型”的表现表示理解和包容。
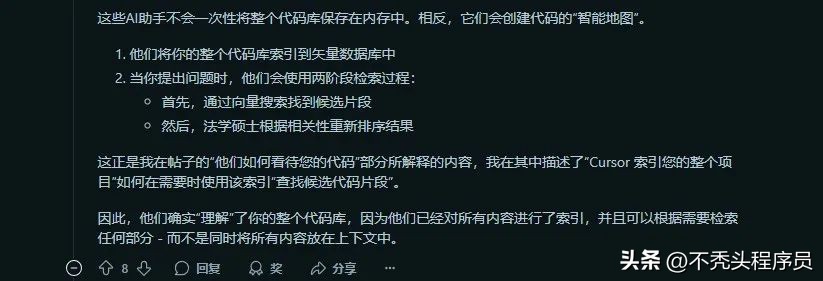
比如有位网友恍若大彻大悟,意识到Cursor其实并不会把整个代码库一次性存进内存,而是通过一种叫做“智能地图”(RAG)的方法,只有在需要的时候才会调用相关的向量索引。
而另一位网友对此表示不满,认为这正是导致这些编码工具理解力不佳的原因所在!
“RAG虽然在处理自然语言时很有效,但用在代码上就不太合适。”他还提到自己遇到的问题:向量搜索怎么知道util.py应该被理解为上下文的一部分呢?
这位网友还认为,只有端到端的测试和顶层UI界面、页面、组件(因为它们涉及自然语言)才适合进行RAG搜索,其它部分则应该通过调用图来判断。
至于修复错误和添加新功能,他认为更好的办法是运行现有的E2E测试,以识别代码并确保覆盖率。
听了这些反馈,大家对工具背后的逻辑有了更深的理解,这对于开发者来说,无疑是打开了新的视角,可以帮助这些编程助手更好地进步。
对于正在蓬勃发展的Vibe Coding来说,这个认识非常重要。虽然目前大家对LLM编程工具的态度比较宽容,但了解算法机制对其他玩家来说,通常能帮助用户提出更优的改进建议。
昨天小编就听到在一个技术交流群里,有朋友反馈说:
Cursor生成项目代码的速度挺快,一两分钟搞定,但是运行后却有很多bug,尤其是语义错误,修复这些问题的时间常常需要半个小时以上。
关于Cursor的代码理解问题,听听用户怎么说
其实呢,Cursor在理解代码的时候,确实遇到了一些难题。这可不是短时间内大模型能解决的。前几天我看到一位网友提到,这个问题的根源在这里:

所以啊,如果Cursor想改善它的“理解力”,或许该认真听听用户的反馈:用RAG来处理代码的上下文效果不太理想,换个调用图可能会更有帮助!








对Cursor和Windsurf的算法解析真是开眼界,了解它们如何理解代码和意图后,使用起来会更顺手。
了解Cursor和Windsurf的核心算法真是受益匪浅,这让我对AI编程助手的运作机制有了更深刻的认识,以后使用这些工具时会更加得心应手。
文章揭示了Cursor和Windsurf背后的算法机制,让我对它们的工作原理有了更深入的理解,确实很实用!
文章中对Cursor和Windsurf的算法分析非常详细,尤其是它们如何理解代码和意图的部分,确实让我对这类工具有了新的认识。