
编辑 | 杜伟、陈陈
你听说过吗?如今决定 AI 能力上限的不再是基础模型,而是外围的「推理编排」(Orchestration)。
有意思的是,在 LLM 完全保持不变的情况下,只需要靠一套 Agentic System,就能让 AI 的智力表现突飞猛进。
最近,有人看过初创公司 Poetiq 的「AI 推理和自我改进系统」的最新评测后,得出了这样的结论。

以下是部分截图
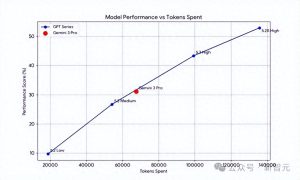
最近,Poetiq 透露他们在 ARC-AGI-2 测试集上,运用了他们的 meta-system 对 GPT-5.2 X-High 进行了测试。这个测试集通常用来评估当前最佳模型在复杂抽象推理任务中的表现。
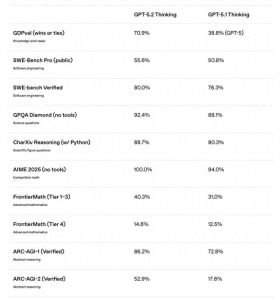
结果显示,在同一个 Poetiq 测试平台上,GPT‑5.2 X‑High 在完整的 PUBLIC-EVAL 数据集上得分高达 75%,这比之前的最佳模型高出大约 15%,而且每个问题的成本都低于 8 美元。
PUBLIC-EVAL 是 ARC 测试的一部分,前者一般包含基础推理和标准的 NLP、数学推理测试,适合各种模型评测,数据集公开且标准;后者则更复杂、具有挑战性,考察模型的抽象推理、常识推理和创新能力,是对高水平模型的推理极限测试。

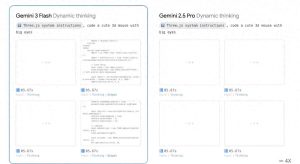
下面的图展示了各个 SOTA 模型在 PUBLIC-EVAL 数据集上的成绩分布:
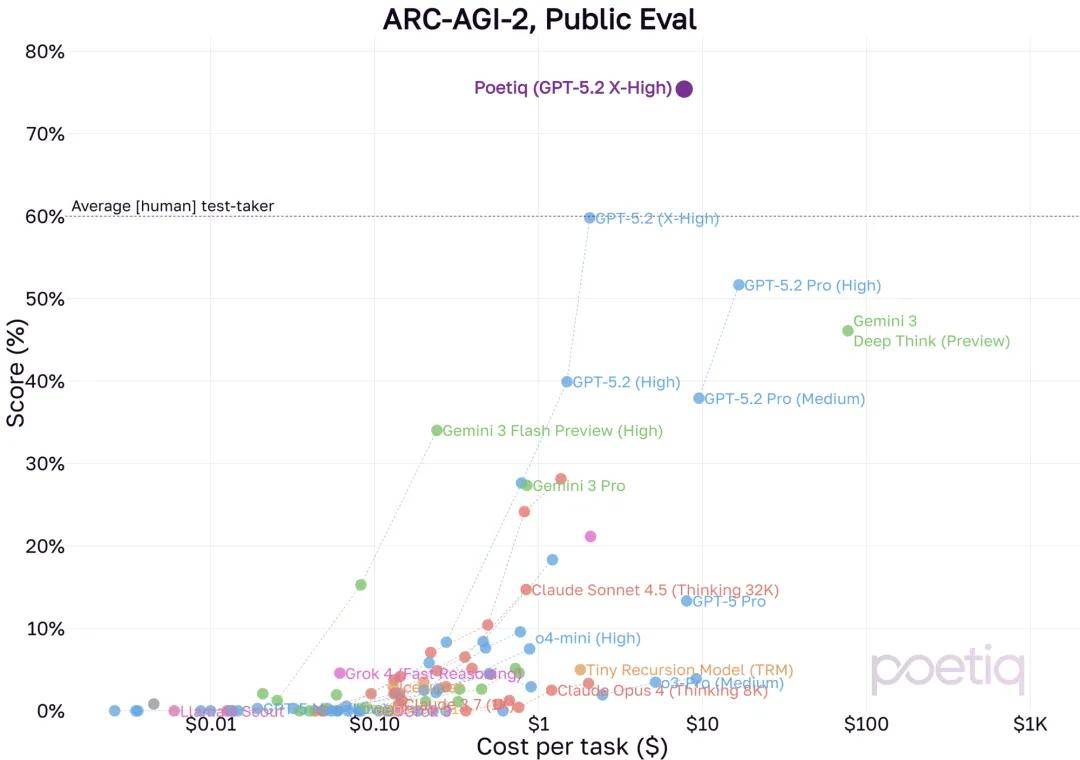
Poetiq 特别指出,他们没有对 GPT-5.2 进行任何再训练或特别的参数调优。
在这么短的时间内,GPT-5.2 在准确性和成本方面都相较于 Poetiq 之前在 PUBLIC-EVAL 数据集上测试的其他模型有了显著的提升。
Poetiq 还设想,如果在 PUBLIC-EVAL 测试中取得的好成绩能够延续到 ARC Prize 的 SEMI-PRIVATE 测试中,那么「GPT-5.2 X-High + Poetiq」将会是史上最强大、最优越的系统组合。
ARC Prize 的总裁 Greg Kamradt 表示,「看到 Poetiq 发布 GPT-5.2 X-High 的成绩我很高兴。如果这个表现能够持续下去,他们的系统似乎能很出色地处理模型切换。不过在 OpenAI API 的基础设施问题解决之前,结果还不能算完全确认。」
这里提到的模型切换是指:系统能够通过更换不同的模型来应对各种任务要求,而不需要对系统或模型进行大幅度的调整或重新训练。

OpenAI 的总裁 Greg Brockman 也转发了这一消息,表示 GPT-5.2 在 ARC-AGI-2 测试中超越了人类的基准成绩。
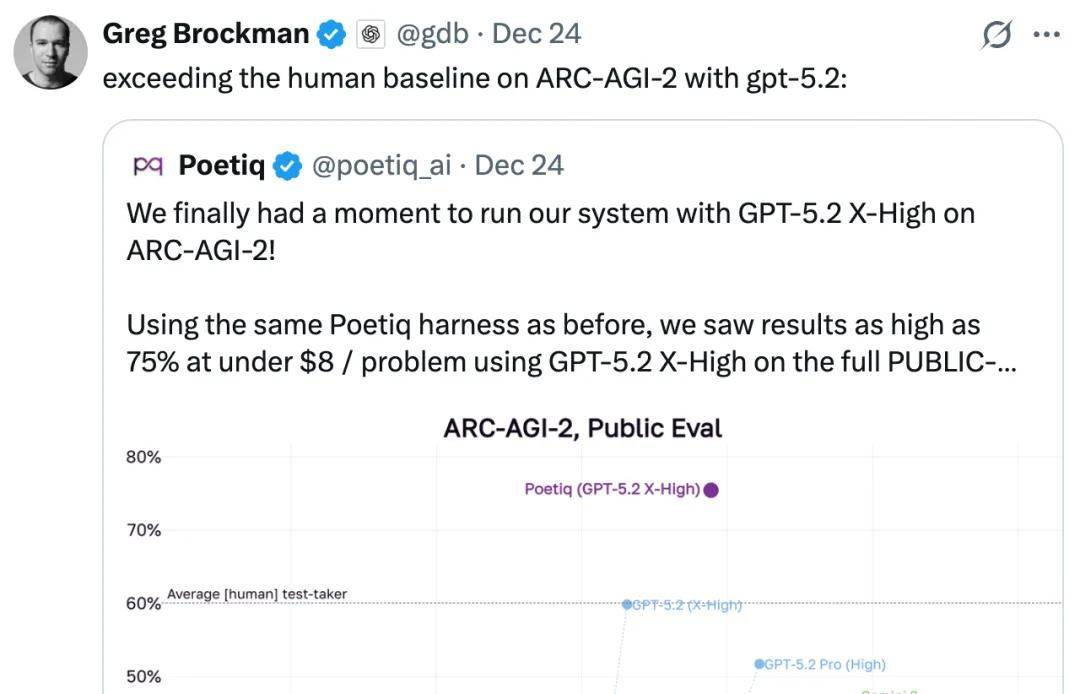
关于这些新测试结果,评论区涌现了许多疑问,比如「每个任务平均需要多长时间来完成?」
对此,Poetiq 回复说,「目前我们还没有专门收集这些数据,但最简单的问题大概在 8 到 10 分钟之内就能搞定,而最复杂的问题则需要在 12 小时内终止,以确保在时间限制内。所以,未来肯定还有很多改进的空间。」
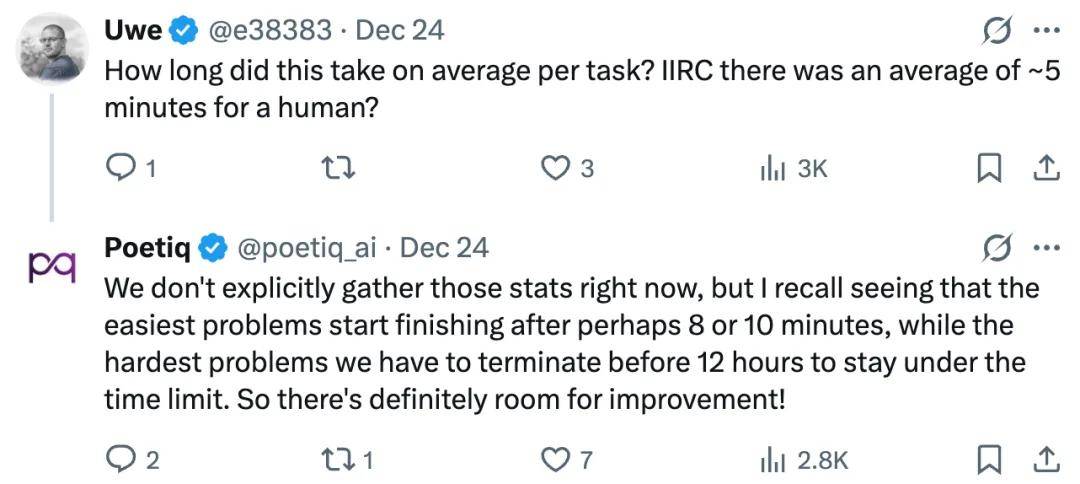
有些人提到,大多数的进步似乎源于测试框架和协调机制,而非模型本身的细节调整。就算没有对训练进行更改,ARC-AGI-2的性能仍然提升了大约15%。这说明在搜索、路由和终止逻辑方面,依然有巨大的提升潜力。
但这里有个疑问:为什么在这个设置下,X-High的每个任务成本反而比High还低呢?是因为它能更快找到合适的解决方案,还是因为测试框架更积极地剔除了不必要的推理过程?
对这个问题,Poetiq明确表示,X-High确实是比High更迅速地收敛到了正确答案。
6人团队打造Meta-system系统
Poetiq的团队只有6位研究人员和工程师,其中不乏来自Google DeepMind的专家。
- Ian Fischer(联合创始人兼联席CEO):曾担任Google DeepMind的资深研究员;
- Shumeet Baluja(联合创始人兼联席CEO):同样是出自Google/DeepMind的资深专家。
Poetiq取得的这些成就,离不开他们构建的元系统(meta-system)。
这个元系统不依赖于特定的模型,能与任何先进的模型配合,比如Gemini 3、GPT-5.1、Grok等,而不是去微调或训练模型本身。这意味着它能快速适应新发布的模型,提升性能。
Poetiq的元系统采用了一种迭代推理的方式,和传统一次性生成答案的方法截然不同,主要有两个机制:
- 迭代式问题求解循环:系统并不是只问一次,而是利用大型语言模型(LLM)生成潜在的解决方案,之后收到反馈并进行分析,再次调用LLM来改进方案。这种多步骤的自我优化过程,让系统能够逐步构建和完善最终答案。
- 自我审计(Self-Auditing):系统可以自主审查自己的进展,判断何时信息已经足够、当前方案是否满意,从而决定是否结束整个过程。这种自我监控的机制对于节省不必要的计算资源、降低整体成本至关重要。
Poetiq还特别强调,他们的元系统适配工作是在新模型发布之前完成的,系统甚至没接触过ARC-AGI任务集,但依然在多个模型上取得了跨版本和跨模型族的性能提升,说明这个元系统对推理策略具有很好的适应性。
正是这种灵活、强大且具备迭代能力的架构,让Poetiq这样的小团队能够在短时间内实现一系列领先的成果。
对于这个元系统,有人认为「真是太厉害了!在模型之上构建智能,而不是在内部构建,意味着可以在几个小时内适应新模型,这真是个高明的办法。成功适配开源模型并迁移到新的封闭模型,表明捕捉到的正是推理过程的基本规律,而非模型的特定特性。」
标题:智能模型的创新之路,真是让人惊叹!

参考链接:
https://poetiq.ai/posts/arcagi_verified/





Poetiq的系统真是颠覆了AI的传统思维,GPT-5.2的表现让人惊讶,未来的AI应用可期。期待看到更多实用案例!
Poetiq的创新系统让GPT-5.2的表现如此出色,75%的准确率真是一个惊人的突破,未来的AI发展值得关注。
这项技术真是令人振奋,GPT-5.2在没有微调的情况下取得75%的准确率,展示了AI潜力的巨大提升。期待看到更多关于Poetiq的应用案例。
Poetiq的创新系统真是太神奇了,GPT-5.2在没有微调的情况下就能达到75%的准确率,看来未来AI的应用会更加广泛。期待后续的测试结果!
Poetiq的系统展示了AI的无限可能性,GPT-5.2在复杂任务中的表现令人振奋,这样的进步让人对未来的AI应用充满期待。
GPT-5.2在没有额外微调的情况下取得75%的准确率,真的让人惊叹。这样的创新系统可能会彻底改变AI的发展方向,让我们对未来充满期待。