这篇文章主要聊聊 Cursor 编程助手在开发中的实际应用,特别是它的计费方式、工具的使用、对话管理策略以及规则配置等关键点。作者还会分享一些个人的实践经验,帮大家总结出如何高效利用 Cursor 的技巧和避雷方法。
如今,AI 编程辅助工具发展迅速,Cursor 凭借其卓越的互动能力、深度集成的代理模式以及对代码的精准理解,迅速赢得了开发者的青睐。不过,随着用户量的增加和功能的复杂化,大家逐渐发现:Cursor 其实并不是个“无限免费”的工具,而是需要精心规划和高效利用的智能助手。
特别是在 0.50 版本发布后,Cursor 统一了计费方式,并加入了 MAX 模式等新功能,这让用户在享受强大功能的同时,也面临了一些新的挑战。本文将基于我在实际项目中频繁使用 Cursor 的经验,整理出一份给开发者的避坑指南。
计费模式
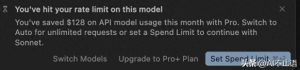
首先得了解 cursor 的计费方式,很多朋友以为开通会员后就能无限制使用,结果很快就用完了额度。其实在之前的版本中,计费方式比较难以追踪,容易超出预算。但在 0.50 版本之后,Cursor 统一了所有的计费模式,无论是代理模式还是聊天模式,都是按照交互次数来算的。简单来说,你问一个问题,Cursor 回答一次就算一次交互。每个周期有 500 次免费的交互额度,超出后就得额外付费(我记得是每次 0.15 美元),或者只能用排队模式,体验就没那么好了。
在这种计费模式下,我们应该尽可能在一次对话中让 Cursor 完成更多的任务,而不仅仅是问一些简单的问题,得充分利用每一次交互的价值。
另外,Cursor 规定在一次交互中最多可以使用 25 个工具,比如读取文件算一个工具,搜索文件夹也是一个工具。如果超过 25 个工具的话,Cursor 会需要你继续执行,这样就会额外消耗一次交互次数。不过一般来说,普通请求很难超过 25 个工具,所以通常不会遇到额外请求的问题。
在使用 Cursor 的过程中,不同模型的费用也是不同的:
深入了解Cursor工具
接下来,我想和大家聊聊Cursor里的工具使用,这些工具能帮助你更高效地运用Cursor哦。
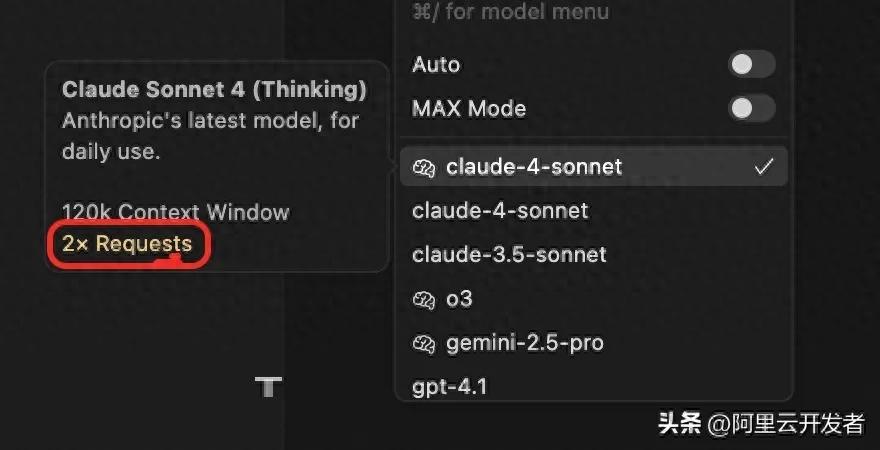
当你打开模型的选择框时,可以看到不同模型的价格变化(上周这个模型的价格还是0.75x)。举个例子,如果你用的是深度思考的Claude,那么每次交互就得消耗两次额度。所以在日常使用时,建议根据你的需求来选择模型。Cursor默认是自动选择模型的,但我觉得最好还是手动选择,这样能更好地考虑到经济因素。我们在开发代码时,可以优先选择Claude的最新版本,至于是否需要深度思考,那就看个人偏好了,我觉得它们之间的差别并不算太大。
最后介绍一下Cursor的MAX模式,可以把它想象成Cursor的“超级赛亚人”模式。它支持更大的上下文,取消了25次工具的限制,读取文件的行数也增加了。不过,相对的,费用也就变得非常昂贵了。MAX模式不再是按交互次数收费,而是按照大模型的费用进行计费,中间还会收取20%的服务费。尽管收费方式依然是按照次数来计算,但看似只用了一次交互,实际上可能会被计算成10次。比如我在计费重置之前,用MAX模式写了一个mcp工具,一下午就消耗了300多个交互次数。
这里给大家分享一下Cursor的计费面板地址:
https://www.cursor.com/cn/dashboard。在控制台里,你可以随时查看自己每月的使用额度和重置时间,建议大家经常关注一下,以免超额使用影响到使用体验。
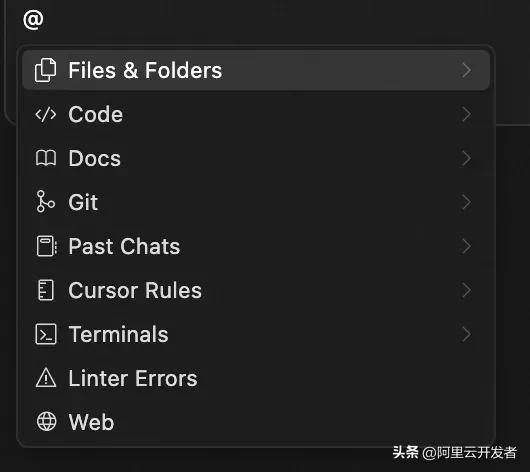
在对话中,你可以通过@来手动指定一些工具。大致的功能如下:
- files&folders:可以读取文件和文件夹,让Cursor专注于某些特定文件;
- docs:指定文档给Cursor查看,如果文档链接以/结尾,Cursor会读取该链接下的所有网页,非常适合查阅开发说明文档;
- git:可以读取git提交内容,并进行比较,不过这个功能用的比较少;
Cursor的使用小技巧
- 过去的聊天记录,Cursor能分析并融入当前的对话上下文中,非常实用。
- Cursor的规则,后面会详细讨论,通常不在聊天窗口中直接使用。
- 终端方面,如果你在使用命令时遇到错误,可以通过这个命令让Cursor知道,从而帮助你解决。
- 代码规范错误,通常不会太常用。
- 要求Cursor先在网上查找信息,然后再进行互动,这个功能用得不多。
多对话框的使用技巧
如果你在使用agent时,直接点右上角的加号开新窗口,当前的工作流就会暂停,这可真不方便。

这种情况体验会很糟糕,可能会浪费交互的机会。不过,Cursor其实支持后台运行对话框,你可以用ctrl(command)+T来新建对话框。
这三个对话框是可以独立运作的,每一个都能单独执行任务而不被打扰。我建议每次直接打开三个标签页,别用右上角的加号,这样能避免打断你的工作流和信息流。
关于对话的中断
在agent模式下,AI有时的表现可能不如预期,但直接重新生成又会浪费时间。Cursor支持在上下文中进行中断,如果你发现生成的文件大多数不符合要求,可以直接重置到检查点。如果大部分内容是正确的,只有最后一小部分出错,可以在错误生成之前的对话框中进行中断。
单一职责原则
在使用cursor的时候,咱们要尽量确保每个对话框专注做一件事情。比如说,如果你有个简单的需求,完全可以在一个对话框里搞定所有功能。但要是需求比较复杂,那就得把它拆分成几个小需求,用不同的对话框来完成。
因为在普通模式下,cursor的上下文是有限的。而且大模型有时会出现幻觉,越长的上下文就越容易出问题。所以我们要尽量保持对话框的上下文简洁,避免因为信息过多导致的误解,确保任务能顺利完成。
不过要注意的是,这里的“单一职责”是针对整个对话框而言,而不是一次交互。其实在一次交互中,咱们还是可以尽量处理多个相关的任务,只要这些任务是围绕同一需求的,避免把无关的任务混在一起,这样反而会影响cursor的表现。
任务拆解
在用cursor完成需求的时候,尽量把你的诉求说得清楚,不要只用一句话概括。你需要详细描述上下文,这样才能避免大模型理解错误,浪费了开发的时间。
举个例子,如果你的需求是要实现一个评价系统,别光说“我想要个评价系统”,而是把它拆分成一个个具体的任务,按顺序列出来,比如:
我需要做一个评价系统,你需要完成以下几项:
1. 使用Evaluation作为评价实体;
2. 创建Evaluation DTO作为数据传输类,并提供Convert工具;
一步步来,轻松搞定评价系统
首先,我们得用Evaluation里的itemId来把商品的id连接起来,这样就能确保每个评价都和对应的商品挂钩。
接下来,咱们需要创建一个EvaluationFacade接口,这个就像是给外部提供服务的窗口,让其他部分可以方便地访问评价系统。
然后,EvaluationFacade这个接口还得具备一些功能,比如用户可以发表评论(包括用户id、评价内容和商品id),同时也要有删除评价的能力(用户id和评价id)。
接着,咱们得实现这个接口,创建一个EvaluationFacadeImpl类,让它真正能够执行这些操作。
还有一点很重要,就是同一个用户对同一件商品只能评价一次,避免出现重复评价的情况。
这样的做法,把需求拆分成一个个小步骤交给cursor去执行,效果会更好,而不是把所有需求一股脑儿丢给它。这样能让AI更高效地完成你的任务。
对话小技巧
值得注意的是,cursor本身不会记得你之前的需求。如果你需要之前用过的代码,直接让cursor去找可能会出错,尤其是在对话已经混乱的情况下。这时,你可以利用cursor的@past chats功能来引用之前的对话。这样,AI就能更好地理解你的上下文,提高任务完成的成功率。
画图+总结能力(汇报神器!!!)
最后,完成需求后,你可以让cursor根据方案总结出一个工作流程图或时序图,可以用plantUML或mermaid格式保存到文件中。这不仅有助于记录,也能直接给cursor看,让它理解某个功能是怎么实现的。
cursor规则揭秘
说到cursor的核心功能,我觉得rules绝对是其中最重要的一环,能大幅提升你的使用效率。接下来,我给你简单介绍一下这些rules到底是什么。
简单来说,cursor rules是cursor在使用中必须遵循的一些规定,所有的会话和代码生成都是基于这些规则。可以把它理解为大模型的系统背景。不过,这些规则并不是一成不变的。比如,像《阿里巴巴代码开发规约》这样的通用规范早就被纳入了大模型的知识库,而cursor的规则则是根据你的个人项目或开发习惯量身定做的,合理制定这些规则能让你的开发工作事半功倍。
cursor rules可以分为user rules和project rules。顾名思义,user rules是针对个人的开发规范,而project rules则是针对项目的开发要求。要查看所有的规则,只需进入首选项里的cursor设置就行。
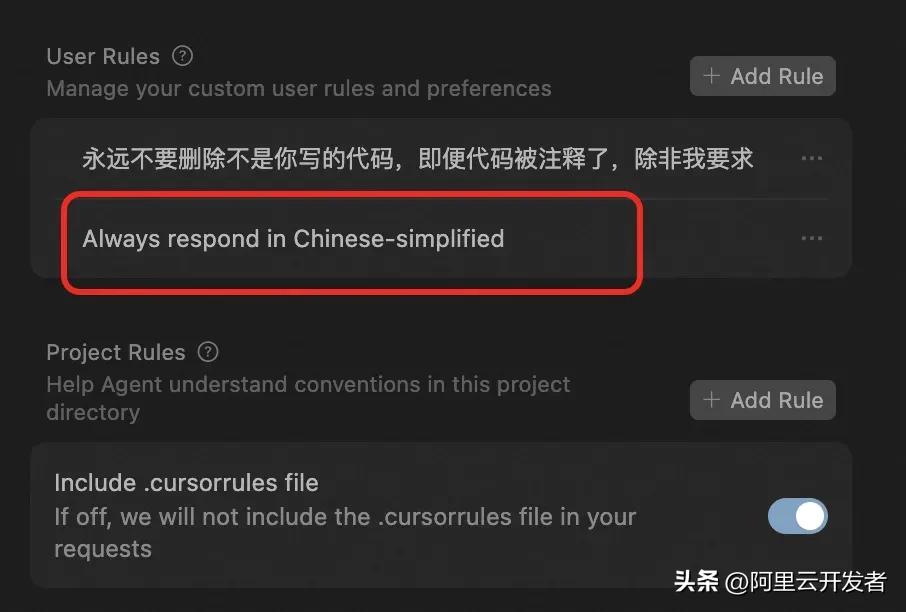
在user rules中,默认有一条规定了大模型的响应语言,其他规则可以通过右上角的“添加规则”来继续增加。
至于project rules,就相对复杂一些。早期版本的cursor只能使用根目录下的.cursorrules文件来设定规则,这限制了我们只能在文件中放入有限的规则。但在最近的更新中,cursor对此进行了优化,现在你可以为项目创建多个规则,并且所有使用cursor进行开发的同事都能共享这些规则。
创建project rules的方法和user rules类似,在user rules下方就能找到创建project rules的选项,还有一个开关可以选择是否使用.cursorrules文件中的规则。
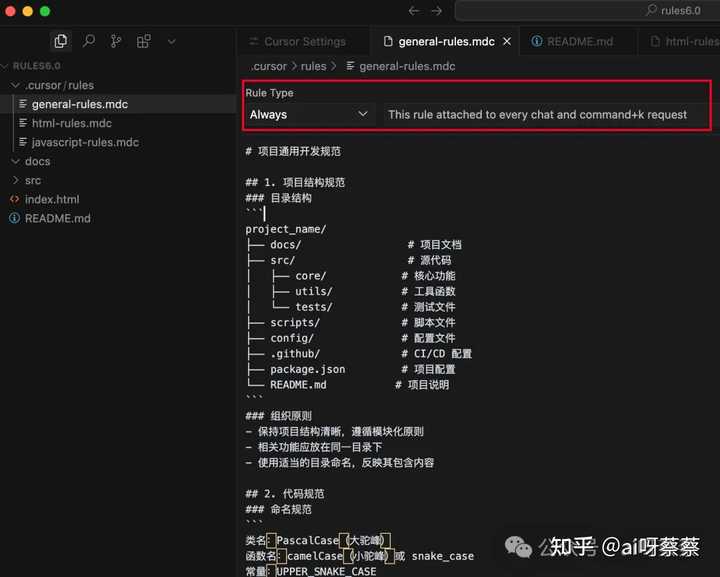
点击“添加规则”后,你会被要求给这个规则起个名字,接着就可以详细描述规则的内容了。
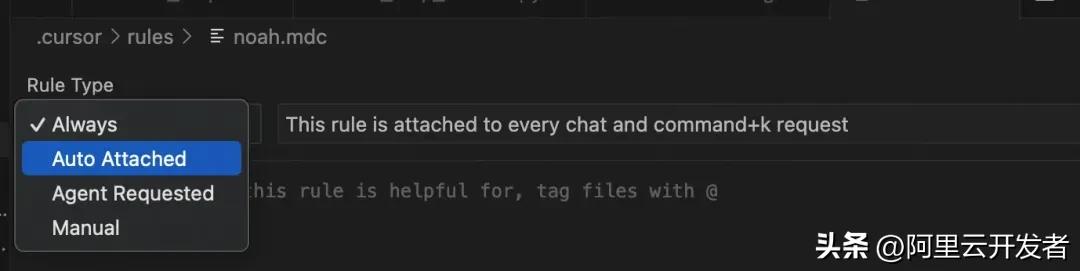
一旦创建完成,就会生成一个.mdc文件,这是Markdown文件的一种扩展格式。你可以像写普通Markdown那样进行编辑。在左侧的ruleType中,你可以选择这个规则的类型,主要分为四种。
各种规则的介绍
- always:这个规则是绝对会被使用的;
- auto attached:这是通过正则表达式来匹配的规则,比如文件的后缀名、格式,或者某个文件夹内的文件;

- agent requested:这个规则是由大模型根据使用场景来判断是否需要调用的;
- manual:这种情况下,agent不会主动调用,除非我们手动指定(其实这种情况几乎不会发生);
你可以根据自己的需求,创建不同类型的cursor规则来使用。
而且,cursor可以帮助你生成具体的内容。如果在定时任务中有一些开发规范,cursor可以直接提炼出每个定时任务的共性,形成相应的cursor规则。或者你只需要给出一些简单的规则,cursor就能根据你的代码上下文,写出完整的规则。
那么,什么时候该考虑修改cursor规则呢?根据我的经验,如果你发现某个规则在开发中需要不停地强调,那就值得将它整理成一个cursor规则。
关于cursor的一些注意事项
cursor无法读取jar包的情况
cursor在判断jar包中的接口时可能会出现问题,因此在创建rpc时,需要清楚说明调用的方法和响应结果,还要明确使用哪个字段。否则,cursor会把响应结果当成object来处理,进而产生无用的代码。这也是生成cursor规则时需要遵循的规范。
cursor可能会选择性懒惰
在解决问题时,如果cursor尝试了多次仍然无果,它可能会选择掩盖这个问题。比如,如果一个验证功能的脚本运行出错,cursor在尝试解决两次未果后,可能会直接修改这个脚本,让验证看起来成功。因此,当你试图让cursor解决问题时,最好避免让它修改验证脚本,必要时可以把这个问题单独提炼成规则。
小心使用checkpoint
在与cursor聊天时,它会在每次对话之前保存一个checkpoint。如果你对生成的结果不满意,cursor会尝试回退到这个checkpoint。不过,如果你多次交互或者开启多个会话,checkpoint的稳定性可能就会受到影响。因此,建议大家还是使用版本管理工具,最好只在单次会话中用checkpoint回退。
谨慎检查cursor的修改内容
每次提交代码时,务必要仔细检查cursor所做的每一处修改,别急着提交。因为cursor可能会改动一些你没预料到的地方,所以一定要确认提交的内容,避免引入意想不到的bug。
Flink CDC 帮助企业实现实时数据同步
传统的数据整合一般需要全量和增量两套系统,完成全量同步后还得进一步合并增量表与全量表,这样的架构太复杂,维护起来也麻烦。这种情况下,Flink CDC技术可以实现统一的实时数据集成,包括增量和全量数据。
点击这里了解Flink CDC实现企业级实时数据同步的详细信息-阿里云技术解决方案。