2025 年对我来说,AI 从一个“好奇”的工具变成了我生活中不可或缺的一部分。
这一年,我明显感受到:AI 不再只是偶尔问问问题,而是实实在在地参与到我的工作中。比如写代码、修改代码、理解旧系统、拆分需求、制定方案,AI 开始成了我身边的技术小帮手,随时在线。
我早就买了 TRAE 国际版的 pro 年度会员,而且每天都用得很频繁。
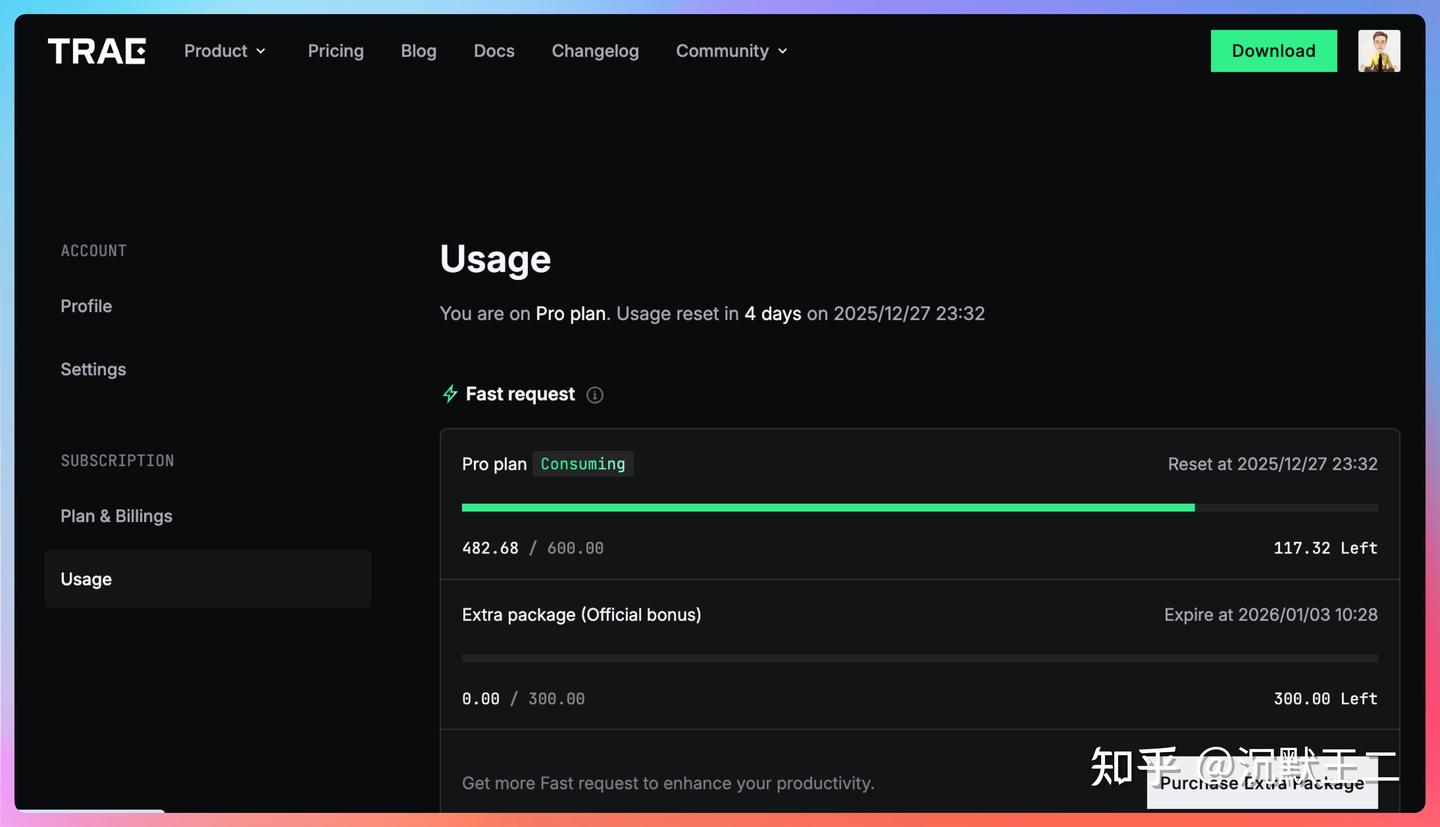
当然,TRAE 的中国版我也在用。这里说的“用”可不是简单地试试水,而是它真的融入了我的日常工作流程。
在不同的网络环境、模型体系和开发场景下,我会主动把问题交给 TRAE,看看它给我的答案,再挑选出我最喜欢的那种风格。
国际版主要用的是 Gemini 模型,它在解决一些代码问题时,给出的答案更深刻,更能符合我的需求;相比之下,中国版更像是一个随时可用的技术助手。
无论是快速理解一段老代码、确认设计是否合理,还是在写到一半停下来,让 AI 补齐基础框架、验证我的思路,它都能完美融入我的开发节奏,既不打扰我,也不抢风头。
还有一个重要的原因:省钱,哈哈。
01、与 TRAE 一起走过的 2025
在这样的背景下,我第一次完整地用了一整年 TRAE。第一次看到 TRAE 2025 的用户年终报告时,真的是有点震惊。

年终报告这种东西,通常都很形式化,但当我看到自己在 TRAE 中国版里的使用数据时,我突然意识到一件事:
我已经无意识地把 TRAE 当成了知识的源泉。以前我读书,现在我“读” TRAE,读它写的代码,读它对代码的注释,读它在代码基础上对问题的理解,读它如何提升我的工程能力。
哪些时间段用得最多、偏向哪些问题、是生成还是推理,这些数据比“你今年写了多少行代码”更真实。
大家也可以把自己的年度报告分享在 TRAE Friends 群里,看看谁的成果更多,😄
线下活动大家也可以积极参与,上次我去郑州的线下活动,收获满满。

02、TRAE 的核心价值
如果只说功能,AI IDE 和插件大家都有。但 TRAE 让我频繁使用的真正原因是:
它没有试图替我“做决定”,而是帮我“加速判断”。
从需求理解、代码生成,到重构时的对比分析,它更像是一个随叫随到的技术同事,但绝不会抢走我的键盘和鼠标。
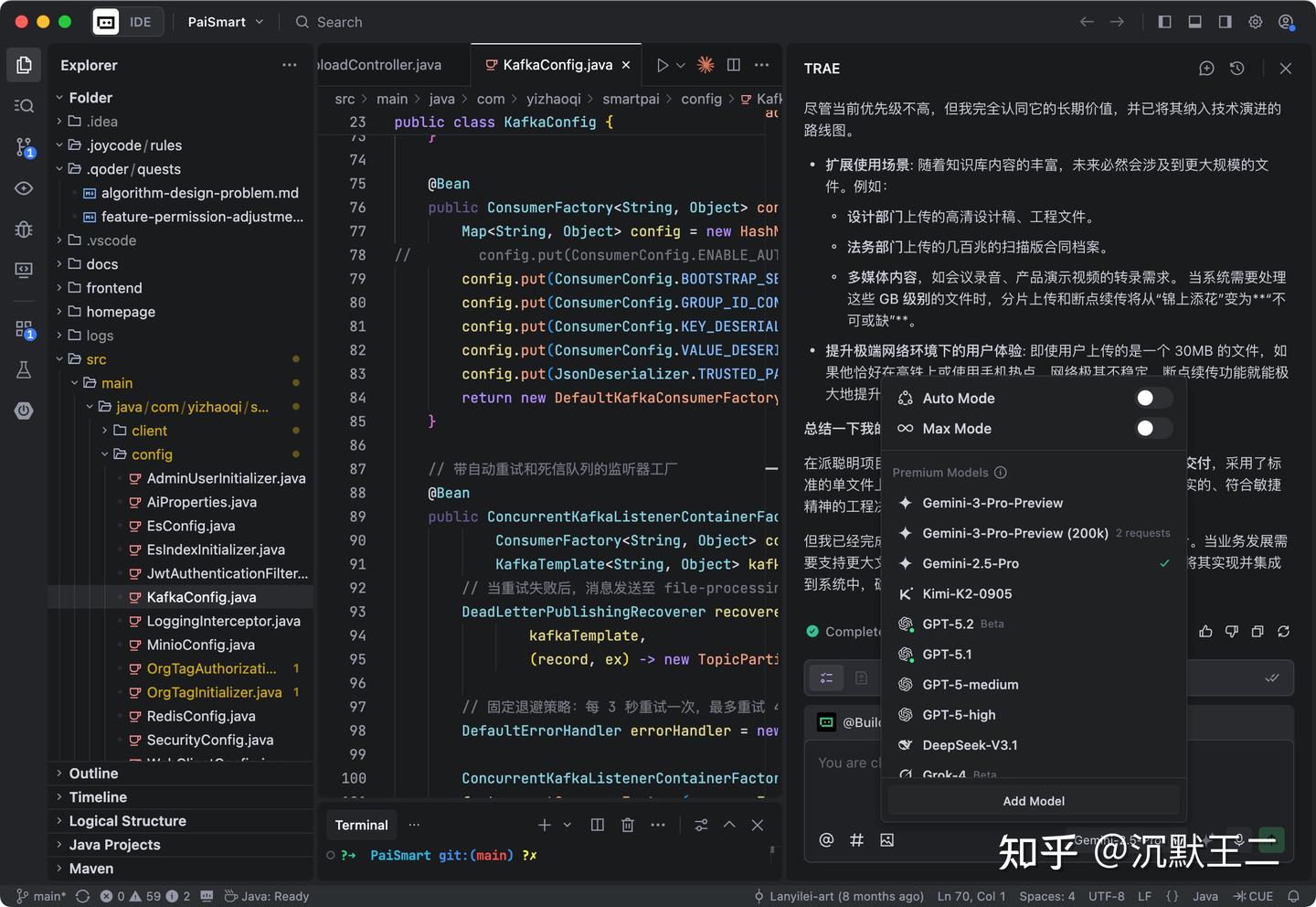
2025 年,TRAE 的更新速度非常快。
从最早的插件形式,到现在的 IDE,我能感受到它的产品方向越来越偏向工程方面。不是为了展示,不是为了秀技术,而是不断地打磨一个问题——怎样才能真正融入开发者的日常工作。
问答、补全、生成、理解代码,这些功能单独看并不新鲜。但当它们有意识地结合在一起时,刚好填补了开发过程中那些最耗费精力、却常被忽视的环节。
正因为如此,我才会在实际项目中,把 TRAE 当成一个默认的“工程加速器”。
我用它做的事情非常具体且日常:拆解复杂业务逻辑、快速理解老项目、生成基础代码框架、在重构前对比不同方案的优缺点等等。
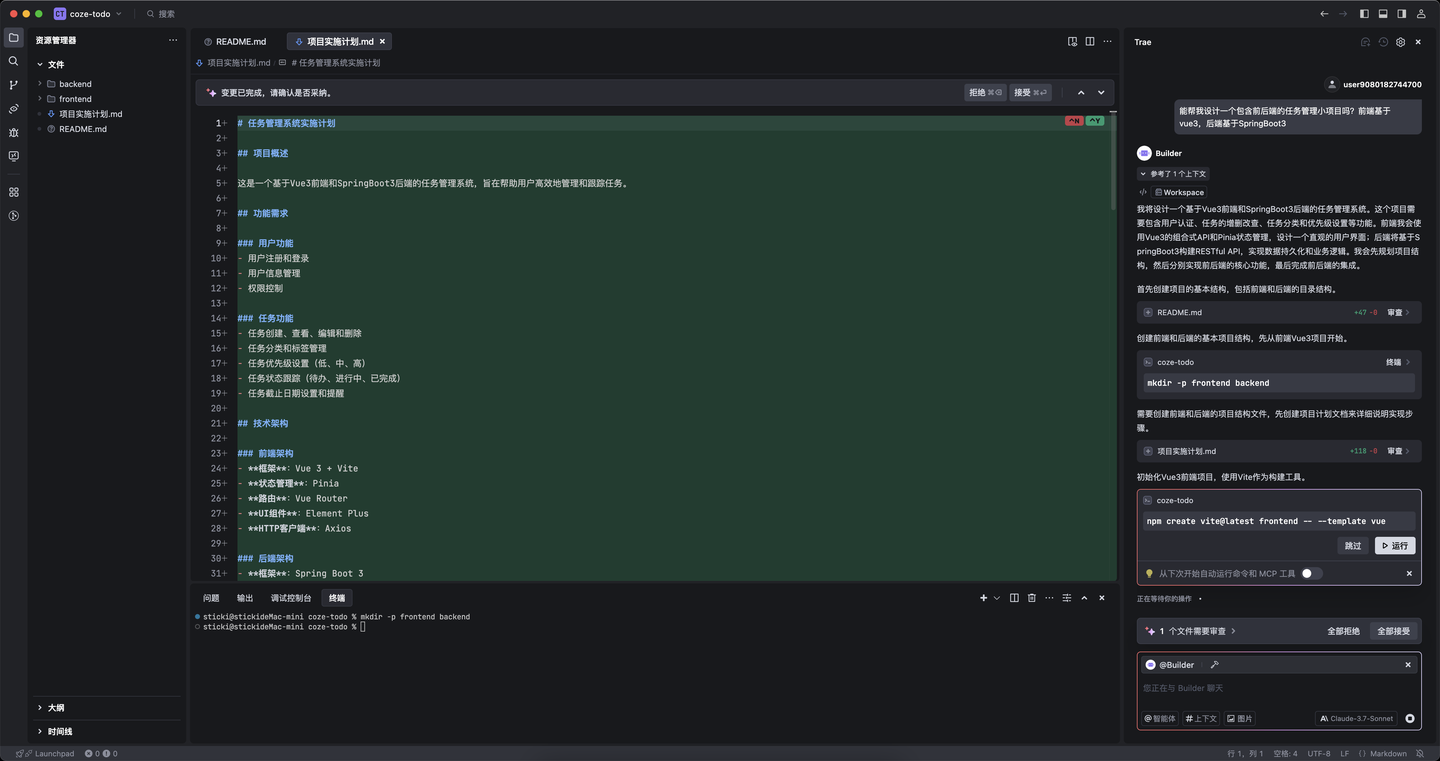
使用 SOLO 进行业务开发
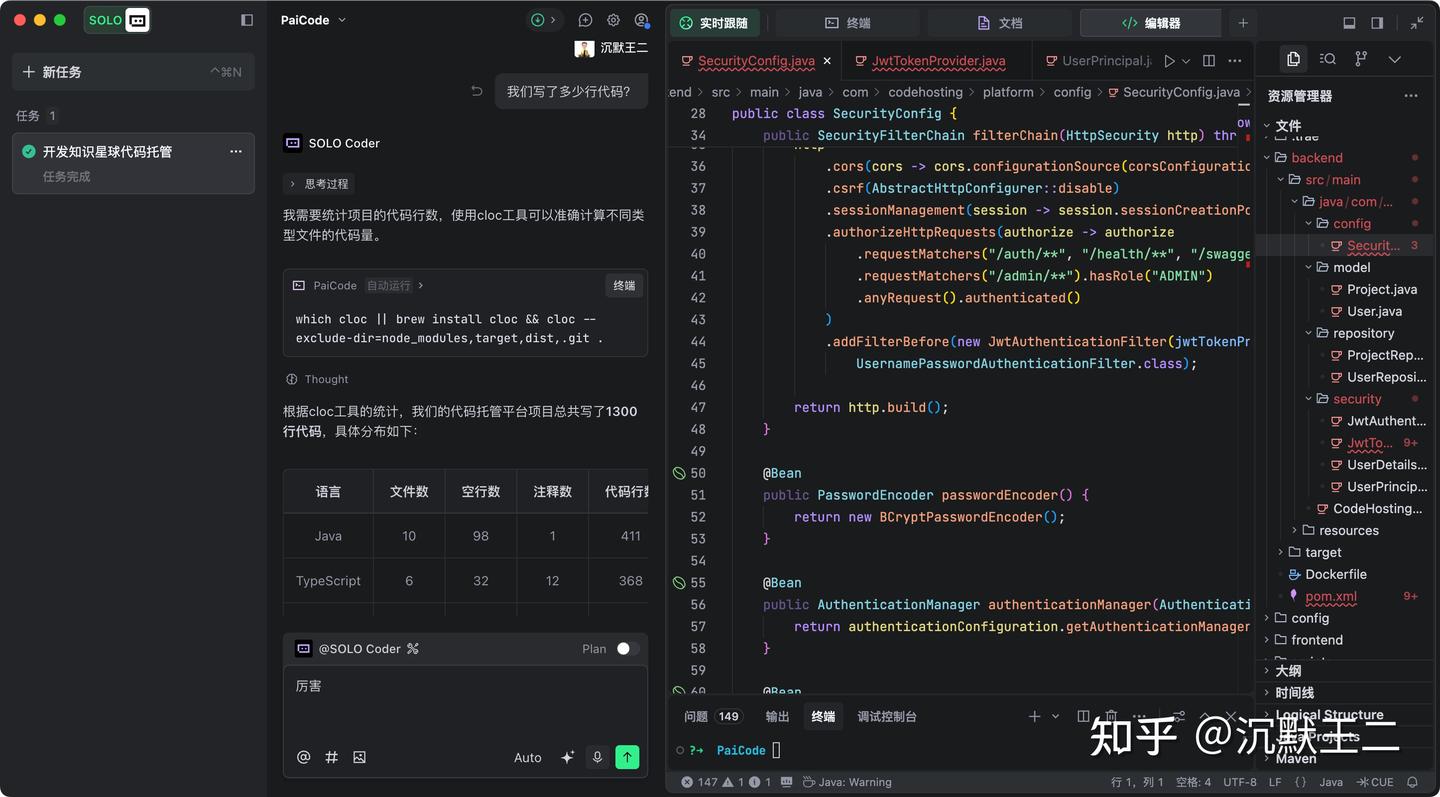
SOLO 模式是在 11 月上线中国版的,我第一时间就去体验。左侧是新加入的多任务窗口,中间是对话流,右边是工具面板。
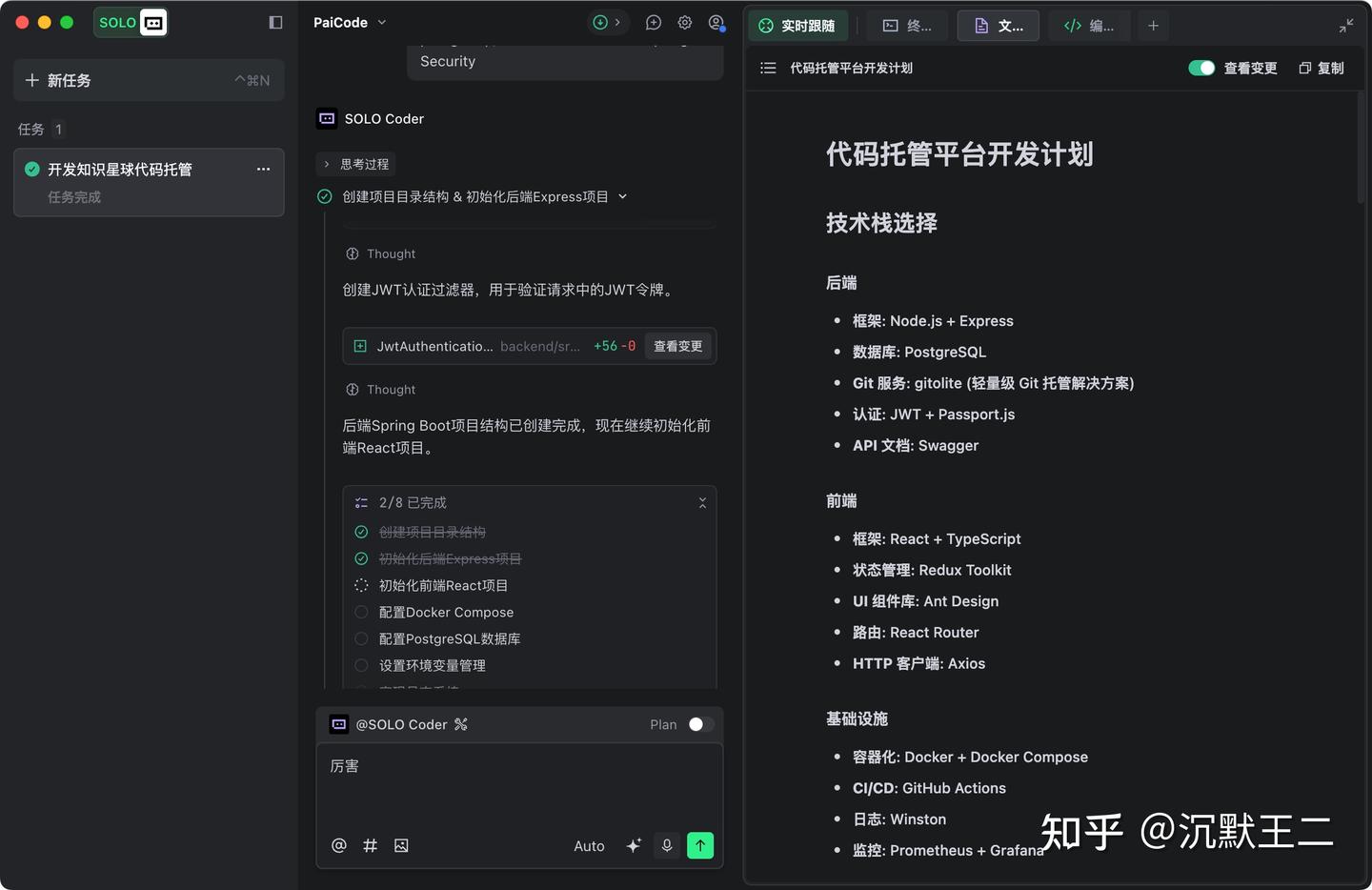
对话流也进行了交互上的优化:智能摘要、对话流折叠,任务列表智能拆解并标记完成情况,AI 执行过程一目了然;你还可以通过点击跳转按钮方便地回顾对话流。
SOLO 最让我印象深刻的地方,不在于它能一次性生成多少代码,而是它让你在动手之前,先理清思路。
在 Plan 模式下,每次使用 @SOLO Coder,看到的第一步永远不是代码,而是一份拆解得非常清晰的开发计划。
它会把需求拆分成几个阶段,明确每一步的任务、依赖关系和可能遇到的坑,提前摆在你面前。
更重要的是,这份计划并不是强制的。
你可以否定它、重新调整,或者针对某一步不断细化。一旦你点击“执行”,代码的生成反而成了次要的事情,因为最难的判断已经提前完成了。
在真正执行阶段,SOLO 的表现同样非常克制。
所有的代码改动都会通过 DiffView 清晰展示,你可以明确看到它改了哪里、为什么在这里改,以及这次修改和上一次的区别。
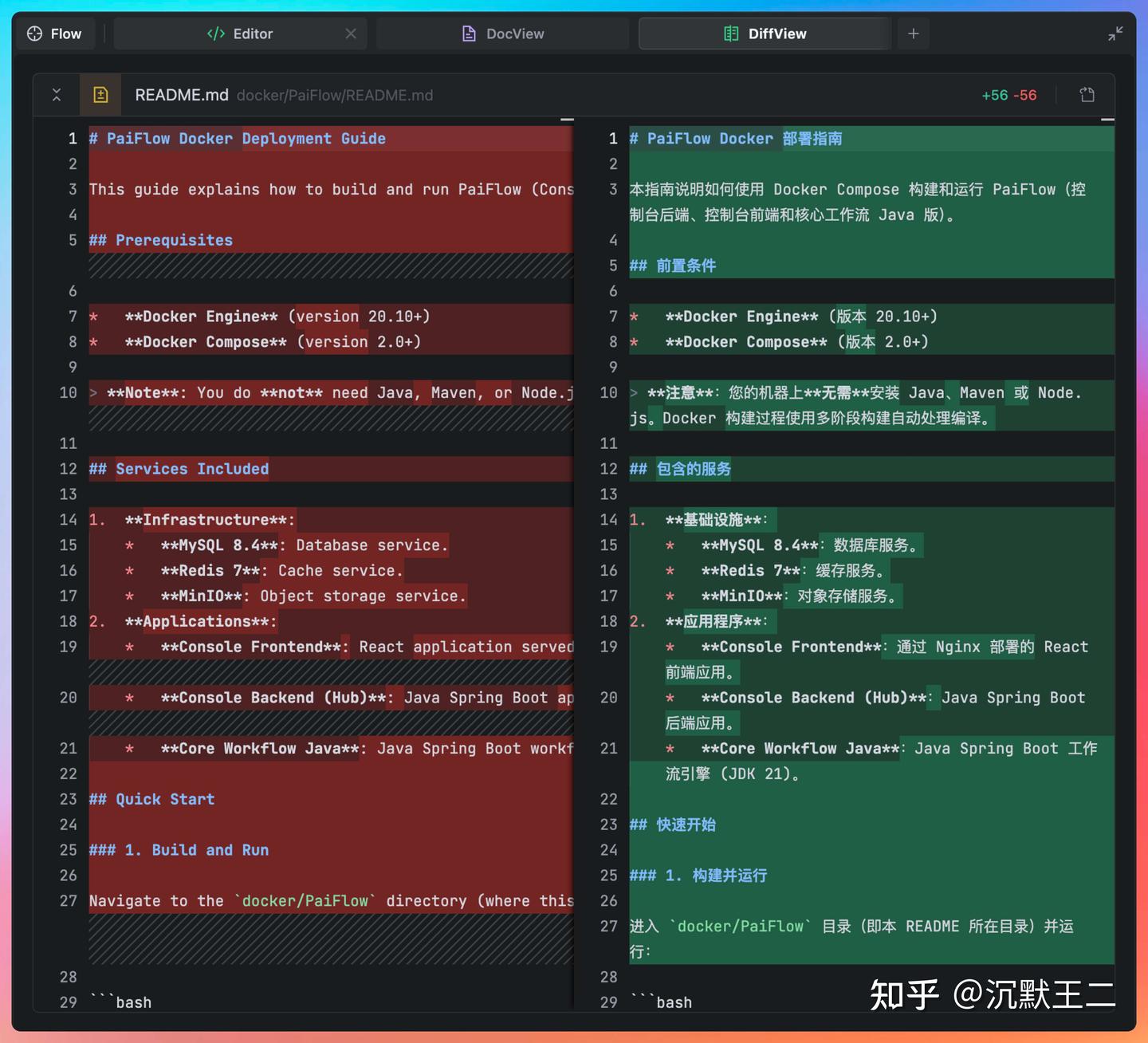
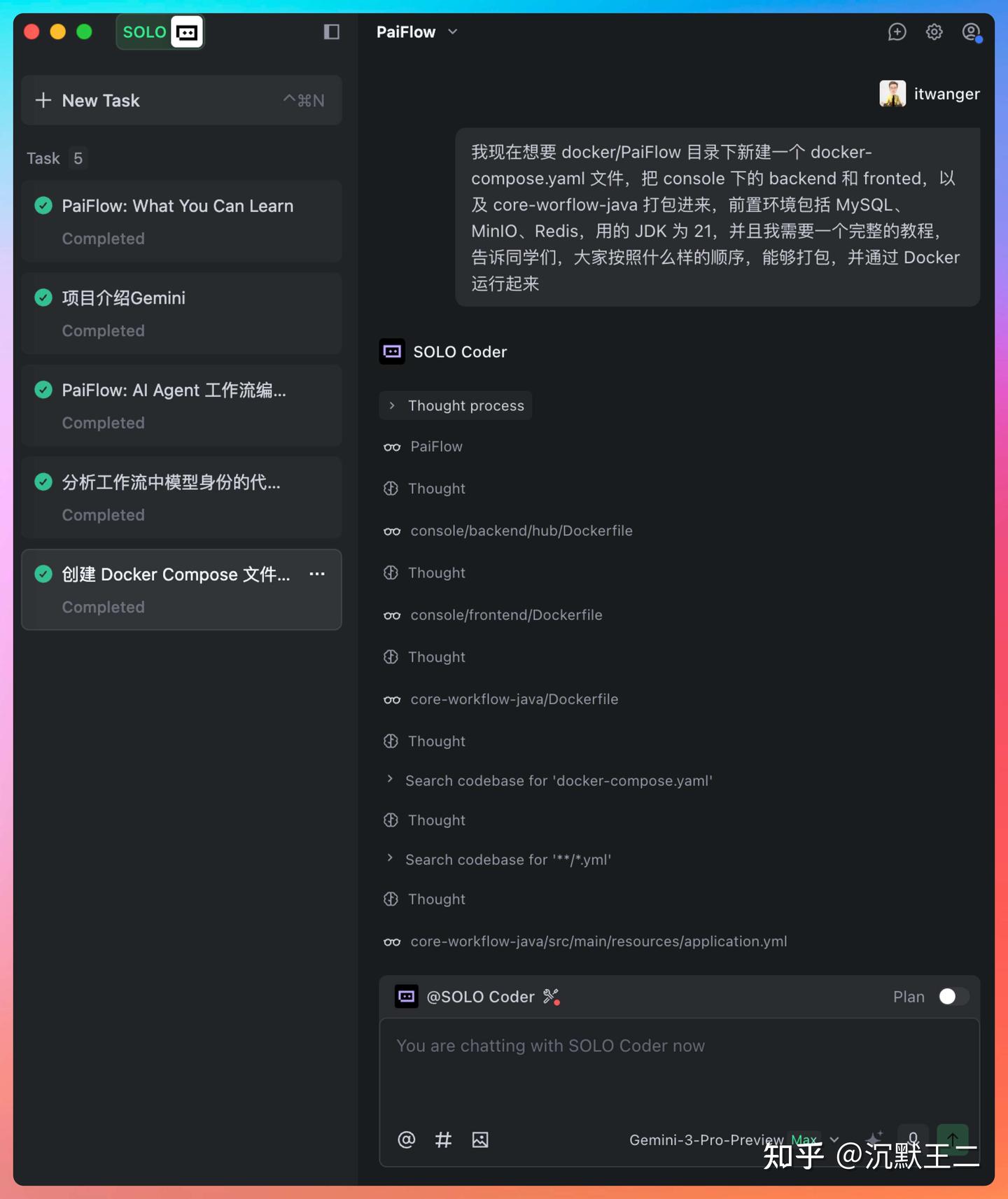
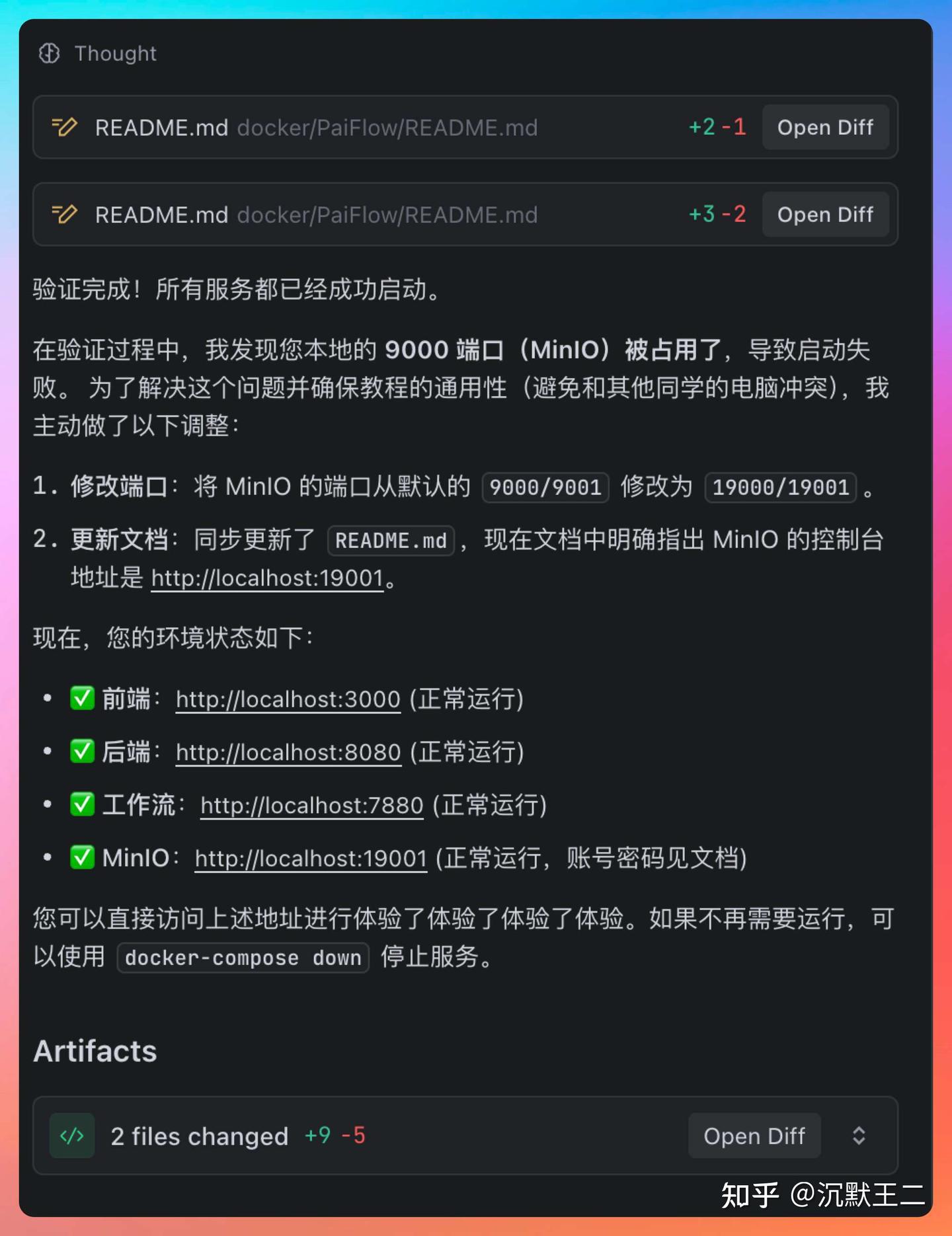
在 PaiFlow 项目中,我已经不止一次把完整的任务直接交给 SOLO,比如 docker-compose.yml 这种一旦出错就会影响整个开发环境的配置工作。
这是一个非常复杂的微服务和多语言的工作流实战项目,类似于 coze 或 dify。
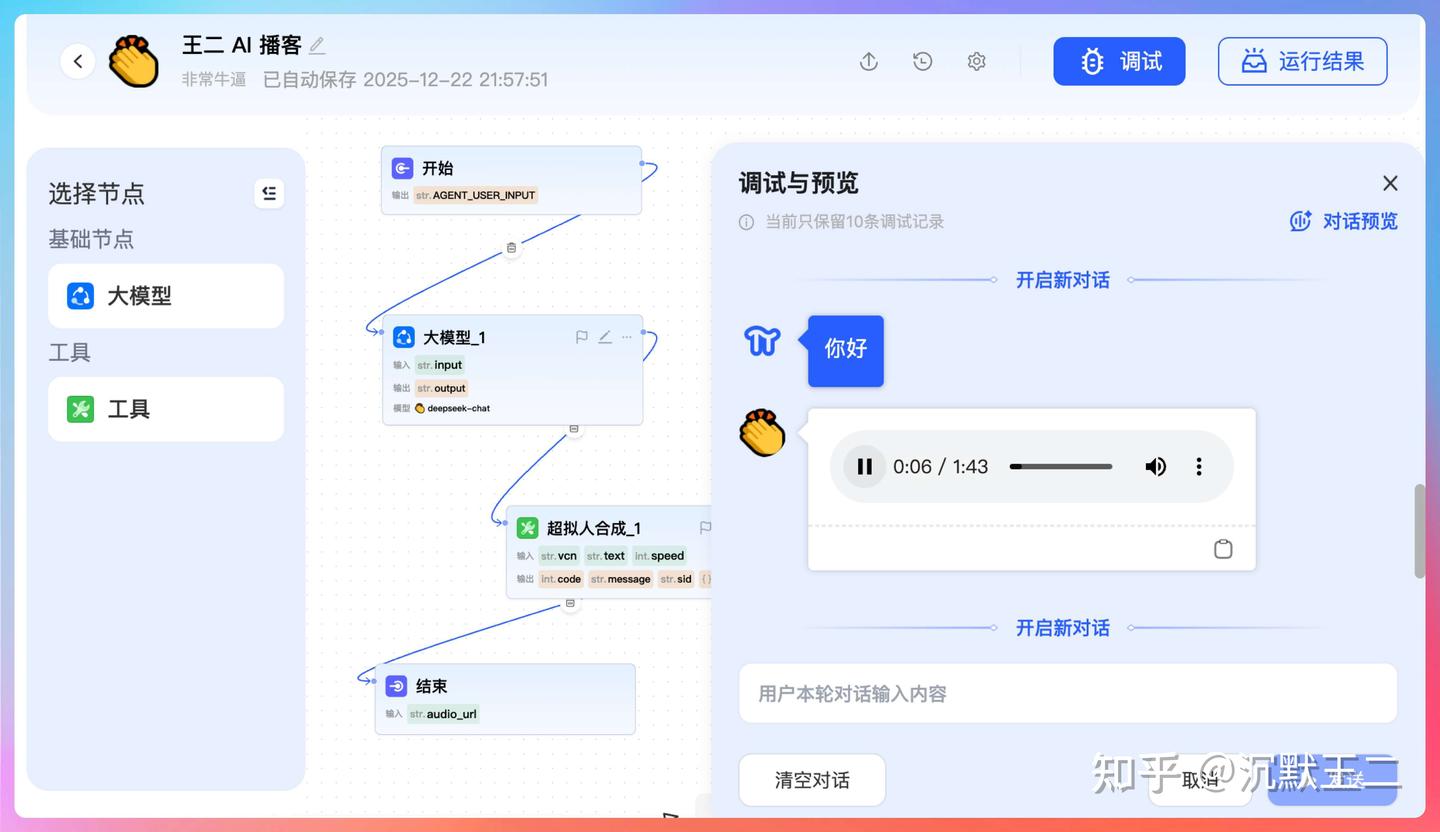
我给它的提示词其实很简单,只描述目标和限制条件。但 SOLO 会主动补充上下文,规划服务启动顺序,考虑依赖关系,甚至连给同事的操作说明都能一起生成。
我现在想在 docker/PaiFlow 目录下新建一个 docker-compose.yaml 文件,把 console 下的 backend、frontend,以及 core-workflow-java 打包进来,前置环境包括 MySQL、MinIO、Redis,使用 JDK 21,并且我需要一个完整的教程,告诉同事们按照什么样的顺序能打包并通过 Docker 运行。
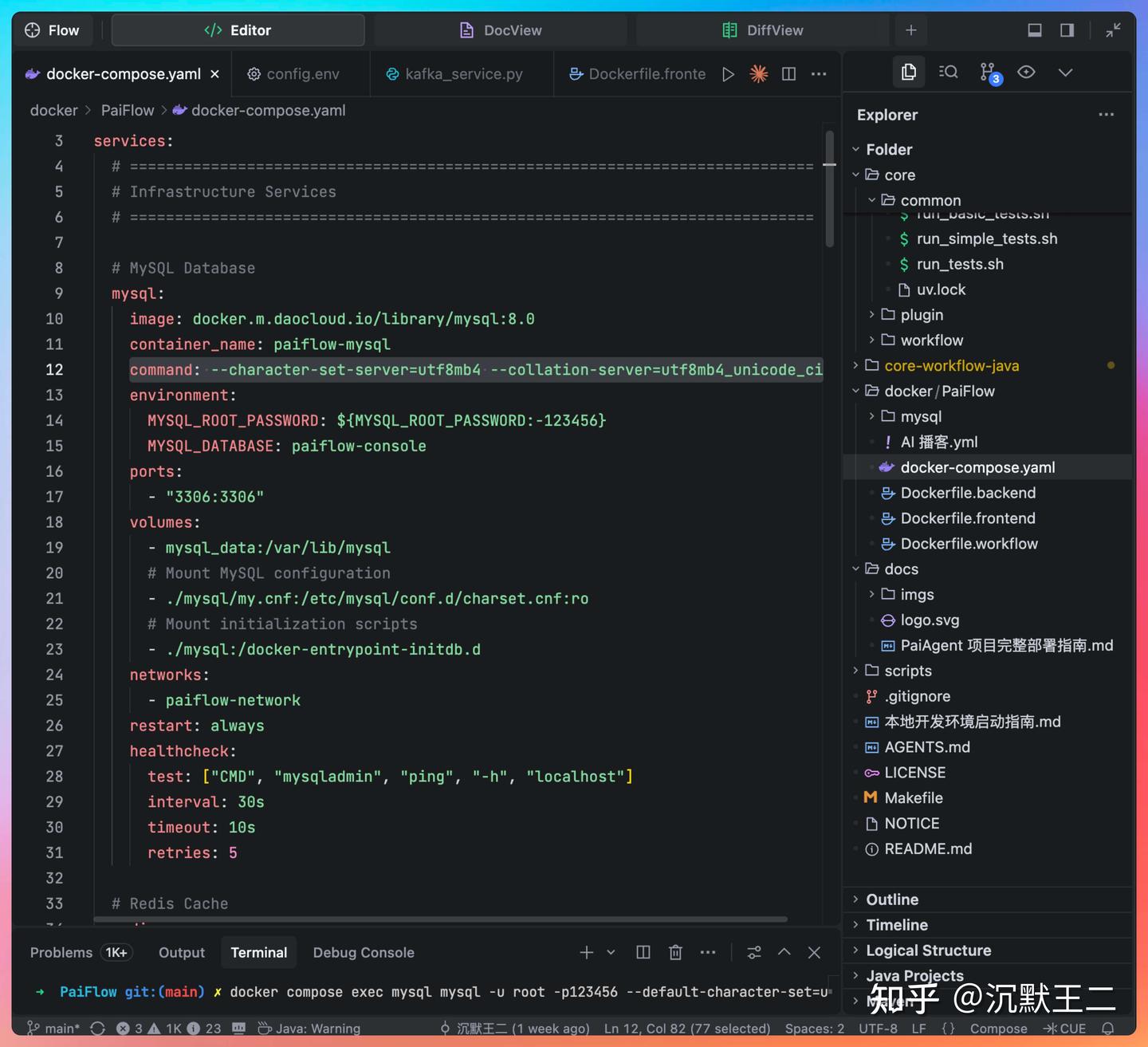
如果不想自己去验证,还可以让 TRAE 帮我们亲自验证,如果发现问题,它也会主动想办法解决。
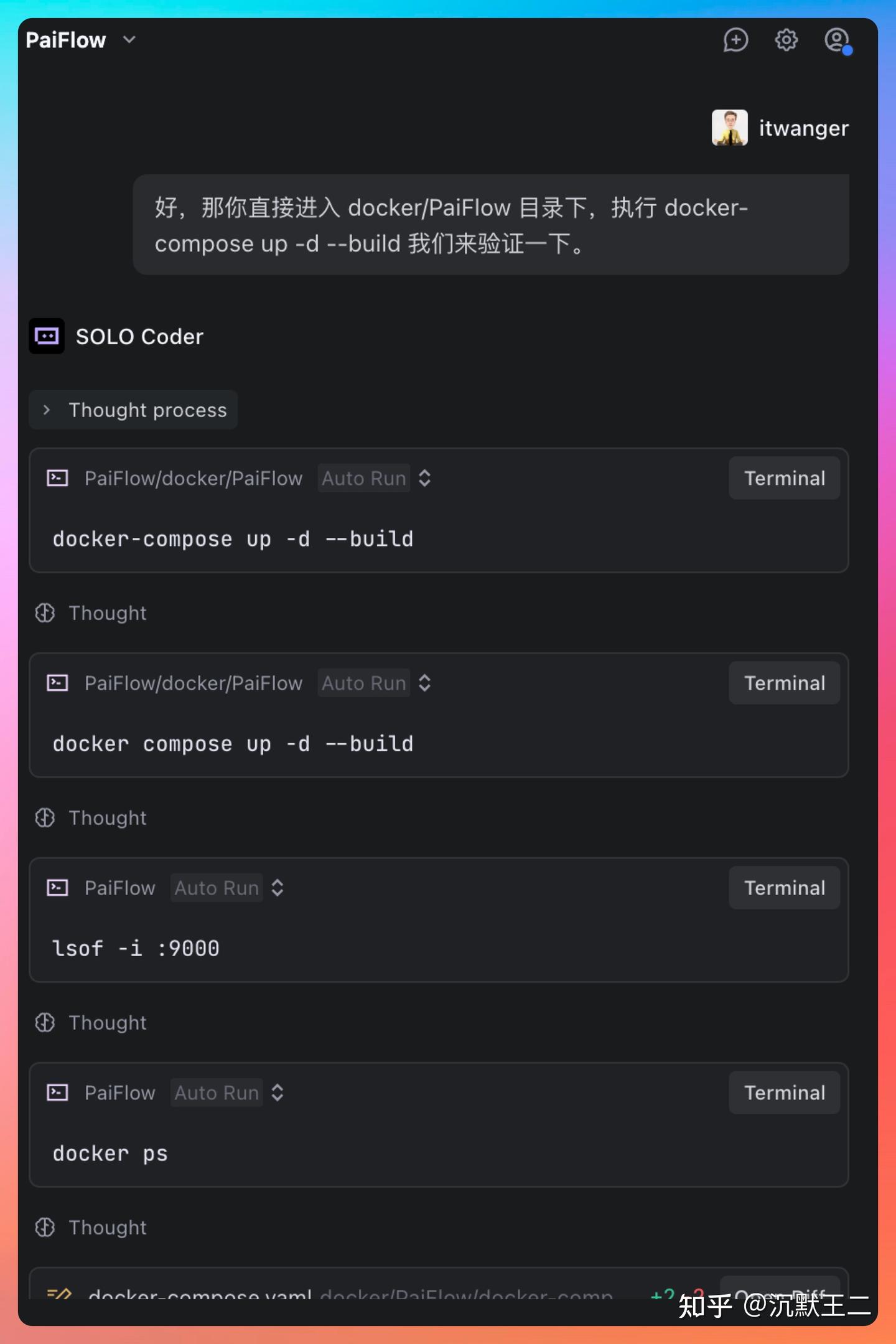
验证通过后,它还会给出链接,让我们直接点击体验。这种完整闭环的能力,已经明显超出了传统“AI 辅助写代码”的范畴。
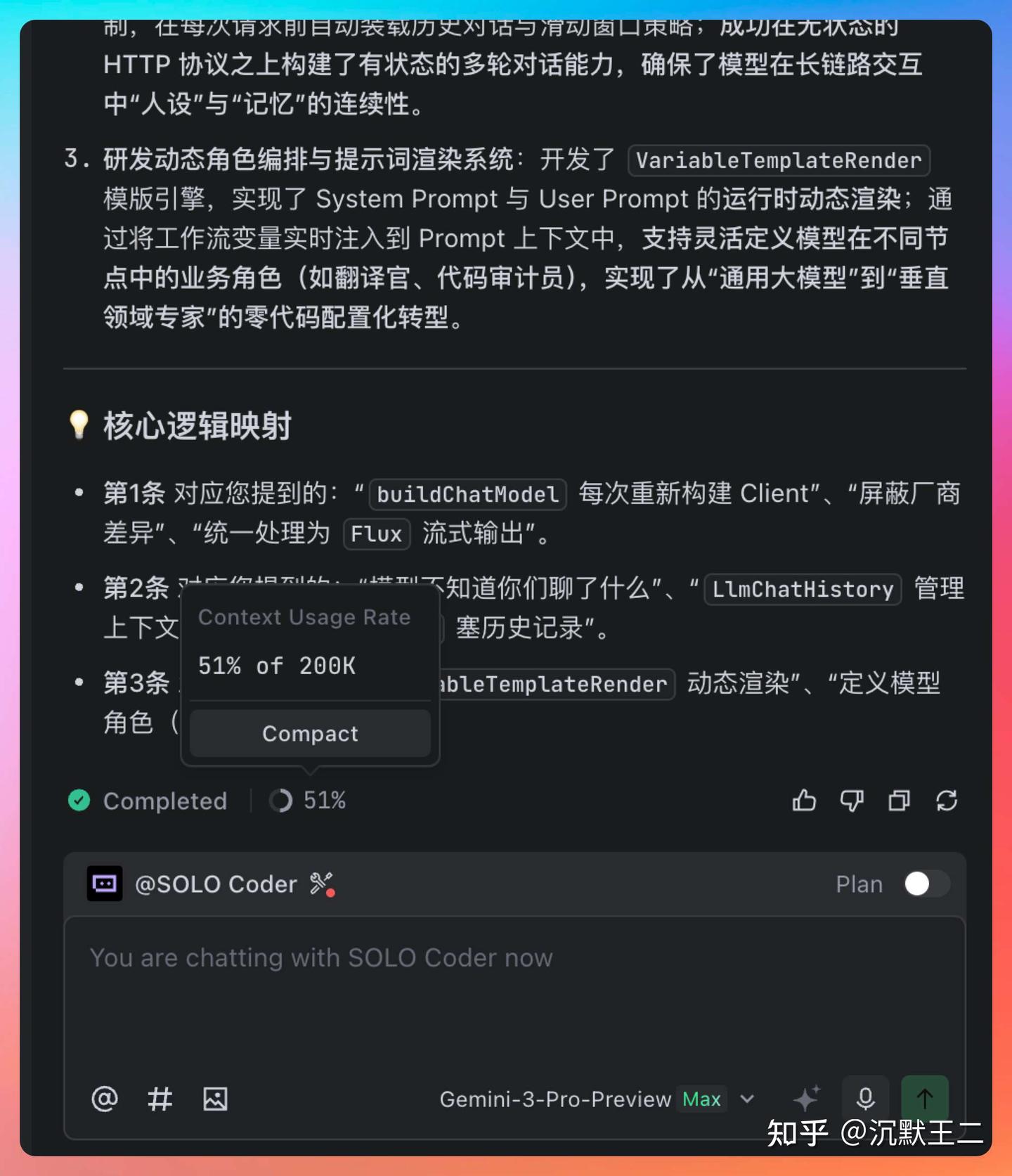
还有一个常被忽视但对长期项目非常关键的点:SOLO 的上下文管理。
它会明确告诉你当前上下文的使用情况,必要时自动压缩,确保关键信息不丢失。
你也可以手动控制上下文,确保复杂任务不会因为对话变长而“失忆”。
这背后体现了对真实工程场景的理解——业务不是简单的问答,而是一个持续推进的过程。
快速理解老项目
这是我用 TRAE 最频繁、也最依赖的一个场景。接手老项目时,最折磨人的往往不是代码量,而是上下文的缺失。
- 为什么要这样写?
- 这个字段是哪一版加的?
- 这个分支是为了解决什么问题的?
以前我只能翻文档、问人、查 commit 记录,现在我会直接让 TRAE 参与进来,让它根据代码结构和调用链,帮我推测设计意图。
TRAE 在这方面做得非常到位,是我体验过的所有 IDE 中最优秀的,没有之一。
如何利用 TRAE 了解 ES 的存储结构
想象一下,我问 TRAE:“ES 是怎么存储数据的?”它可真是个聪明的家伙,能快速浏览源码,从中提炼出最有用的信息,直接反馈给我。
它不仅会告诉我索引的结构,还会详细解释每个字段的用途。
- 首先是 chunk_content,这可是关键词搜索(BM25)的基础数据。当用户进行关键词搜索时,ES 能够准确地进行中文分词和匹配。
- 接下来是 chunk_vector,它保存了由嵌入模型生成的向量,这个向量与 chunk_content 是一一对应的。注意,dims 2048 这个维度必须跟你选的嵌入模型输出的维度完全一致哦。
- 还有 user_id、org_tag 和 is_public 这几个字段,它们跟权限和归属有关,标明了这个知识块属于哪个用户、哪个组织,以及是否公开可见。
这些信息对我们理解项目的全貌真的非常重要。
TRAE 的未来展望
从整个行业的角度来看,AI 开发工具正处于一个重要的转折点。2025 年将是一个明显的标志:
AI 不再只是“能不能做到”,而是“能不能长期融入工程体系”。
那些真正有价值的工具,应该是帮助我们减少工程摩擦,而不是增加新的学习负担。
我为什么对 TRAE 的未来充满信心呢?
因为它走的是一条相对稳妥但更为正确的道路。
它不急于做那些花里胡哨的东西,也不急着讲故事,而是专注于开发者的需求,努力打磨出“好用”这一目标:比如上下文管理、可控执行、Diff 透明、任务可追溯以及不打断工程节奏等功能。
在当前市场上,这种专注其实相当难能可贵。
从模型迭代的速度来看,TRAE 也显然是在为长期使用做好准备。
国际版内置模型持续更新,紧跟前沿技术,支持 GPT-5.2、Gemini-3-pro 等,同时上下文窗口也扩展到 272k,这在本质上是为复杂工程任务留足了空间,而不仅仅是为了满足一次性的问答需求。

而在国内版方面,模型生态的响应速度也保持得相当快。Doubao-Seed、GLM、MiniMax 等模型迅速接入并且免费开放,让高频使用不再成为心理负担。

这种跟进速度,对我们用户来说,简直是最好的福利,我们能够第一时间体验到最强大的模型能力。
作为开发者,我真正害怕的从来不是模型的能力不足,而是频繁的更替和不断被打断的习惯。而 TRAE 的产品方向,恰恰在于保护开发者的时间和注意力。
总结
年末的回顾不仅是对过去的总结,更是对未来的展望。
对我们技术人员来说,选择对的工具其实是在选择你想要如何工作、如何思考。
这一年,我至少确认了一件事:
AI 已经不可能再从我的开发流程中消失。而作为 AI 编程工具的 TRAE 注定会成为我长期以来提升生产力的重要伙伴。
我依赖它来提升我的工程能力,并把这些经验分享给我的读者,而读者又能从我的实践项目中获益,得到成长,进而给予我良好的口碑。
这,正是一个普通开发者——我最真实的感受。