最近,AI编程工具Cursor的表现引起了大家的关注,真的是风头无两。它的强劲性能让人惊讶。最近,Cursor的一位重要研究者参与的论文发布了,里面提到了一种新方法,能够通过自然语言的规划搜索,来提升Claude 3.5 Sonnet等大型语言模型的代码生成能力。
这篇论文的名字叫做PlanSearch(规划搜索),由Scale AI团队主导。文中提到的第一作者是Evan Wang,而第二作者Federico Cassano最近加入了Cursor,他之前参与了GammaTau AI项目,旨在让AI编程变得更加普及。此外,他还是BigCode项目的重要贡献者,负责开发用于AI编程的StarCoder系列大型语言模型。

- 论文标题:Planning In Natural Language Improves LLM Search For Code Generation
- 论文地址:https://arxiv.org/pdf/2409.03733
在论文开头,团队提到了强化学习的先驱Sutton在《The Bitter Lesson(苦涩的教训)》中讨论的Scaling Law的两个重要原则:学习和搜索。随着大型语言模型的发展,大家对「学习」的有效性已经不再怀疑,但传统机器学习中的「搜索」策略在大模型中的应用仍然是个谜。
目前,影响模型搜索能力的主要问题是答案缺乏多样性,往往给出的结果过于相似。这可能是因为模型在预训练后,针对特定数据集的进一步训练,使其适应某些特定的任务。
研究显示,许多大型语言模型往往被调整为只生成一个正确答案。例如,DeepSeek-Coder-V2-Lite-Base的表现不如其基础模型,但当生成答案的多样性降低时,情况恰恰相反。许多模型都出现类似情况,经过特别调整的模型在只输出一个答案时(pass @1)通常表现优于基础模型,但在需要生成多个答案时,这种优势就不明显了,甚至有时会相反。
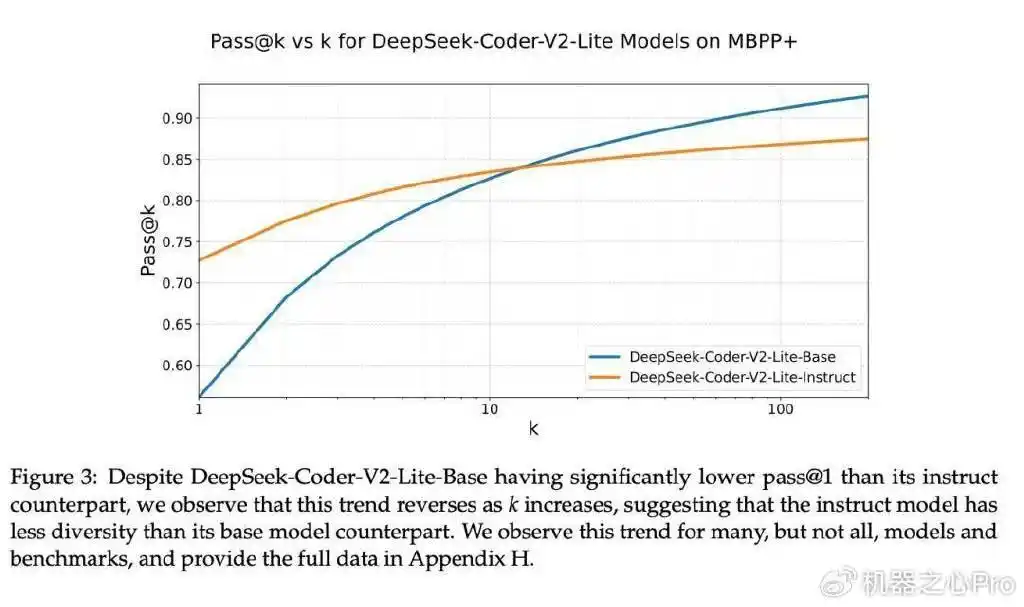
模型在生成答案时缺乏多样性,这对搜索效果影响很大。尤其是在极端情况下,比如使用「贪心解码」时,模型输出的结果会非常相似,因为是从同一个模型中重复抽取的。即使模型花费了更多的推理时间,也难以得到更好的搜索结果。
像LMSYS Chatbot Arena、LiveCodeBench和OpenLLMLeaderboard这样的排行榜,往往无法反映模型在回答多样性方面的不足。它们主要关注模型在单一示例上的成功率,忽略了模型在更广泛场景下的表现。虽然单一样本的反应速度对聊天机器人至关重要,但这并不能全面评估模型在允许更长推理时间时的综合表现。
针对这些问题,研究团队开始探索如何提高大语言模型在推理过程中回答的多样性。他们提出了一个假设:要让模型输出的答案更丰富,就需要在自然语言的概念空间中进行搜索。
为了验证这一假设,研究者们进行了多次实验。首先,如果给模型提供一些简单的草图(这些草图是从已经能解决问题的代码中「回译」而来),模型就能根据这些草图写出正确的最终程序。其次,如果让模型在解决问题之前,先在LiveCodeBench上生成一些思路(这个过程叫做IdeaSearch / 思路搜索),再看看模型是否能用这些思路解决问题。
结果显示,模型要么完全无法解决问题(准确率为0%),要么能够完美解决问题(准确率为100%)。这表明模型在解决问题时,成功与否取决于最初的想法(草图)是否正确。
根据这两个实验的结果,研究人员认为提升LLM代码搜索能力的自然方法是:先搜索正确的思路,再进行实现!
于是,规划搜索(PlanSearch)方法就此诞生。
与以前的搜索方法不同,规划搜索并不是单纯地搜索单个token、代码行或整个程序,而是寻找解决当前问题的可能性规划。在这里,规划的定义是:帮助解决特定问题的高层观察和草案集合。
为了生成新的规划,规划搜索会生成大量关于该问题的观察,并将这些观察组合成候选规划。
这个过程需要对生成的观察的每个可能子集进行操作,以最大限度地鼓励在思路空间中进行探索,然后将结果转化为最终的代码解决方案。
实验结果显示,在推理过程中,规划搜索方法的效果优于传统的重复采样方法和直接搜索思路的方法。
方法
在这项研究中,团队探索了多种不同的方法,包括重复采样(Repeated Sampling)、思路搜索(IdeaSearch)和新提出的规划搜索(PlanSearch)。前两种方法比较直观,这里我们重点关注新提出的规划搜索。
团队发现,虽然重复采样和思路搜索能够有效提升基准评测结果,但在许多情况下,多次提示(pass @k)即使在高温度设置下,也只会导致代码输出发生微小变化,无法改善思路的缺陷。
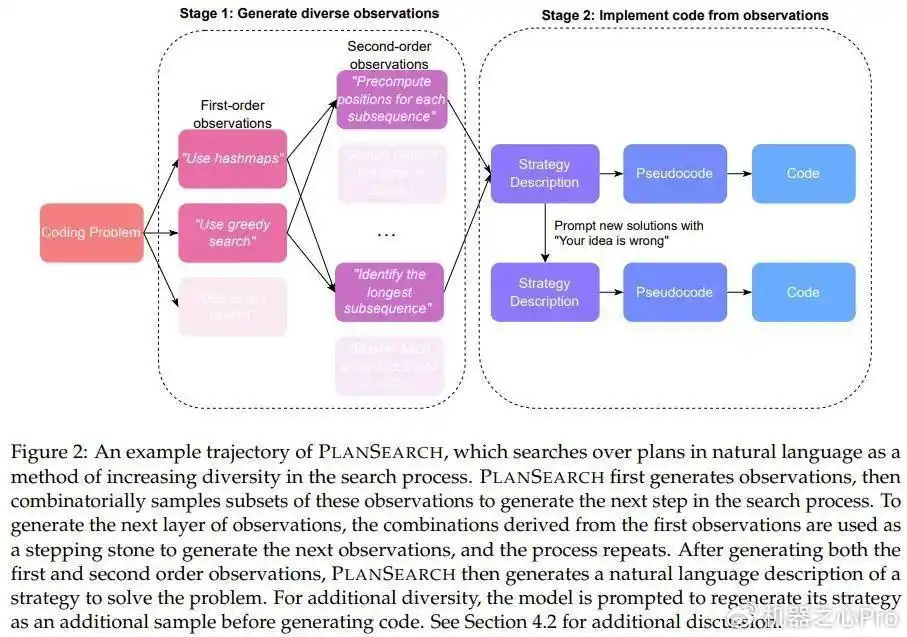
接下来,让我们具体看一下规划搜索的过程:
1. 通过提示获取观察
首先假设有一个问题陈述P,通过向LLM发送提示词来获取对该问题的观察(记作O^1_i,其中i ∈ {1, . . . , n_1}),通常n_1的数量在3到6之间,具体数量取决于LLM的输出。团队会创建O^1_i的集合S^1,包含所有子集,最大大小为2,每个子集都代表观察结果的一个组合(记作C^1_i)。
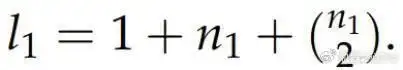
2. 推导新的观察
这样一来,所有观察结果的集合就可以定义为深度为1的有向树,根节点为P,每个C^1_i都有一条从P指向C^1_i的边。
然后,在每个叶节点C^1_i上重复上一步流程,生成二阶观察集S^2。生成二阶观察时,团队会在提示词中包含原问题P和C^1_i中的所有观察,让模型使用这些观察来得出新的观察。
这个过程可以继续进行,但由于计算限制,团队在深度为2时对树进行了截断。
3. 将观察转化为代码
获得观察后,必须先将它们转化为具体的思路,然后再转化为代码。对于每个叶节点,团队将所有观察和原始问题P放入提示词中,调用LLM生成问题P的自然语言解决方案。为了增加多样性,团队还会假设某个思路是错误的,要求LLM提供反馈,从而将建议的思路翻倍。
最后,再将这些自然语言解决方案转化为伪代码,进而转换为真正的Python代码。
实验
实验使用了三个评估基准:MBPP+、HumanEval+和LiveCodeBench,具体参数设置和细节请参考原论文。
实验结果大揭秘:规划搜索如何超越传统方法
说到结果,这个团队可没闲着,他们对三种方法的表现进行了详细分析,分别是重复采样、思路搜索和规划搜索,具体的数据可以在表1、图1和图5中找到。
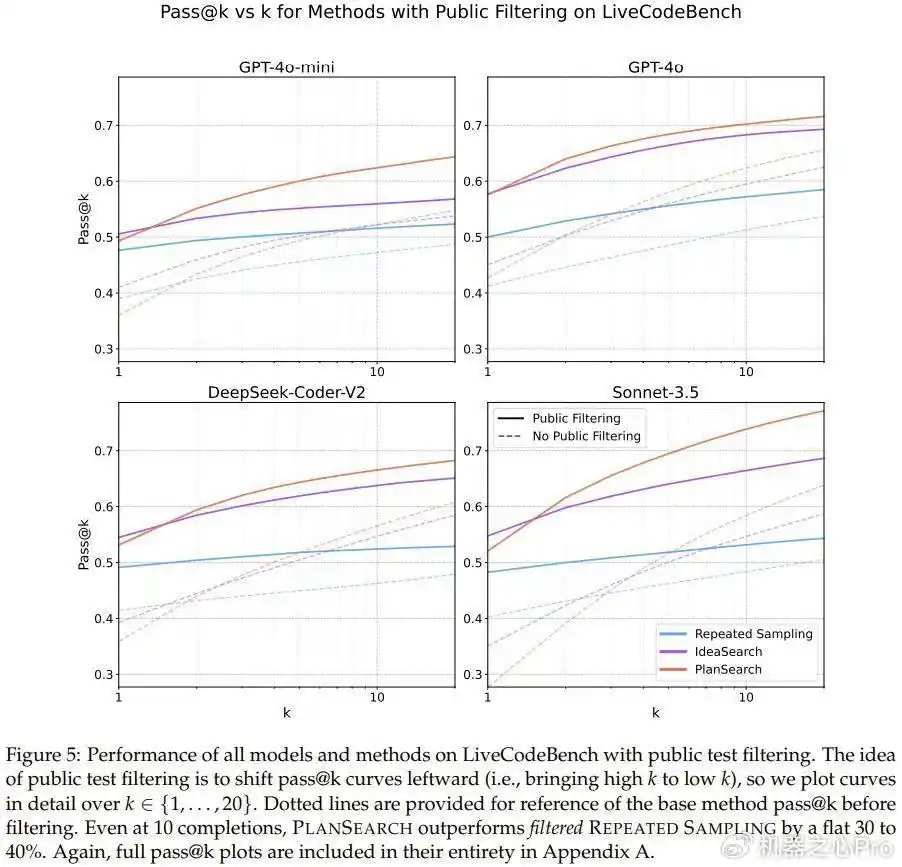
从结果来看,规划搜索和思路搜索的效果明显强于基础的采样方法。尤其是规划搜索,几乎在所有实验方法和模型中都取得了最佳成绩,真是让人惊讶。
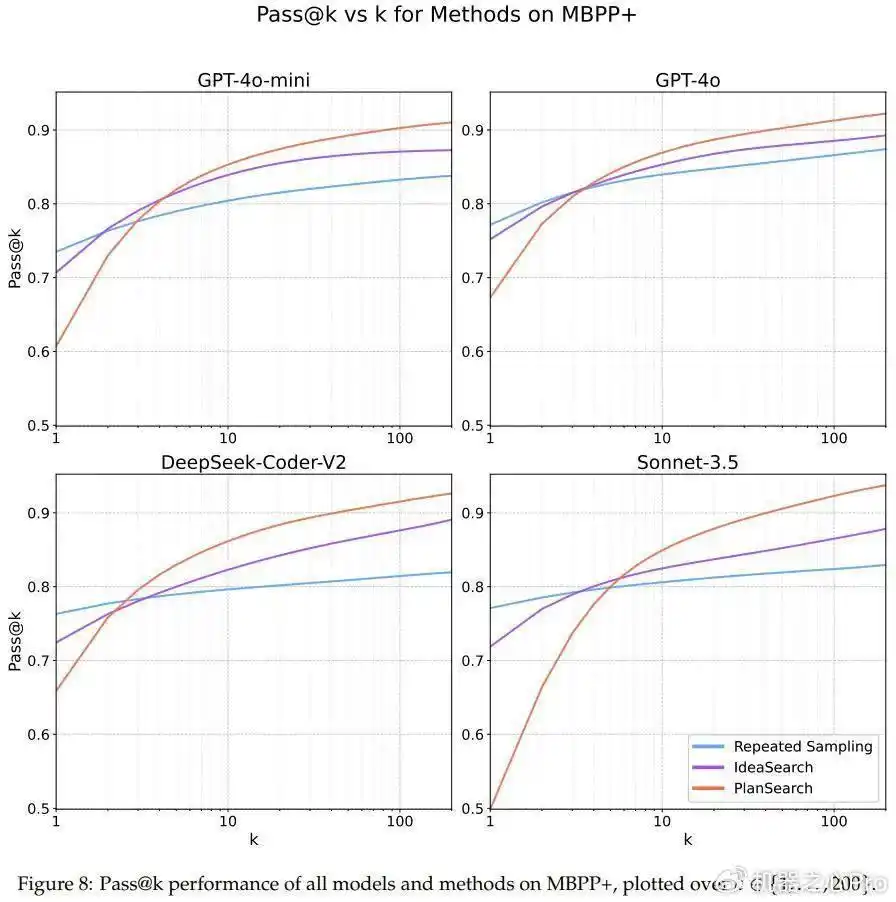
图7、8、9则详细展示了各个数据集上的pass@k的结果,大家可以参考一下。
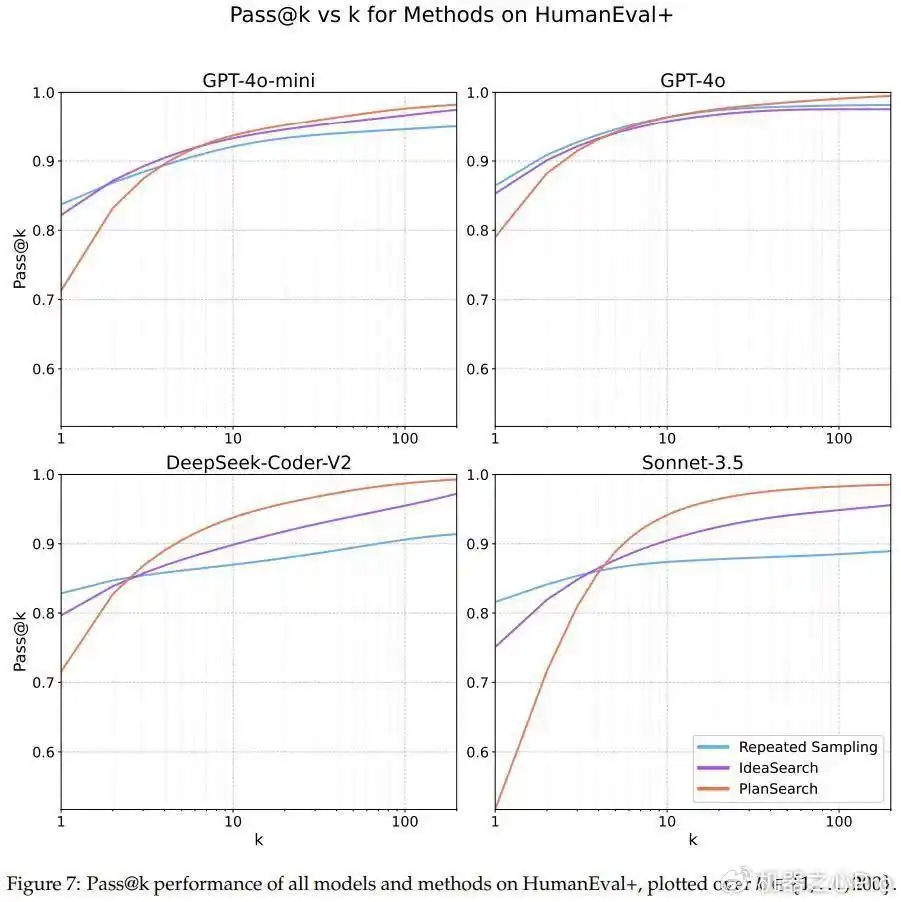
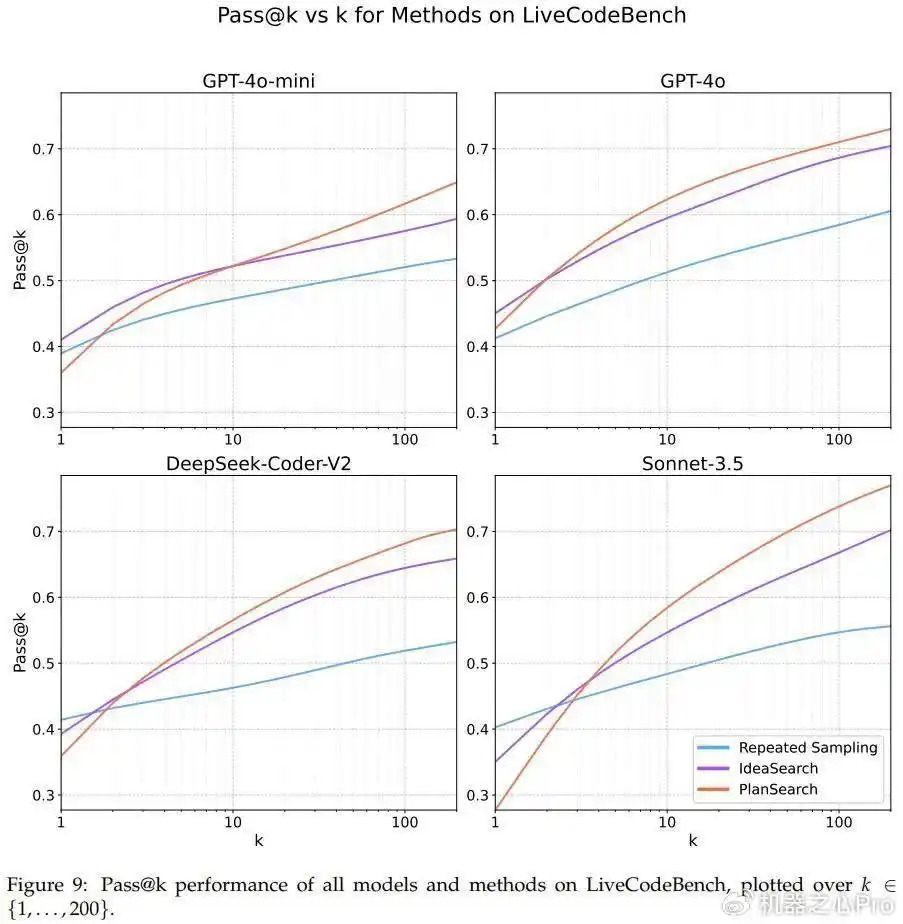
你可能会好奇,在Claude 3.5 Sonnet上使用规划搜索的时候,LiveCodeBench基准下的pass@200表现居然达到了77.0%,这个成绩比不上搜索的最佳分数(pass@1=41.4%)以及传统的best-of-n采样方法(pass@200=60.6%)要好得多。
而且,用一个小模型(GPT-4o-mini)进行规划搜索,仅仅四次尝试就超过了不使用搜索的那个大型模型。这也印证了最近一些关于小模型进行搜索的研究成果。
在其他两个编程基准HumanEval+和MBPP+上,规划搜索同样带来了不小的提升。
通过研究不同模型之间的差异,团队发现pass@k曲线的趋势在所有模型中并不一致,实际上每条曲线都有自己的特点。他们猜测,这可能跟思路的多样性变化有关。
还有个有趣的发现是,规划搜索对某些模型的pass@1并没有什么帮助,尤其是在LiveCodeBench上,Sonnet 3.5的表现最为突出。
团队给出了一个直观的解释:思路多样性的增加可能会降低生成某个特定思路的概率,但同时提高了在思路池中至少有一个正确思路的机会。因此,pass@1可能会稍微低一些,但正因如此,pass@k的表现反而会更好,尤其是在缺乏多样性的情况下。
此外,表1和图1展示了尝试/完成的主要结果,经过归一化处理后,每种搜索方法都可以针对每个问题尝试k次。
最后,团队还发现,思路空间中的多样性可以用来预测搜索性能。他们通过计算模型/方法的pass@1与pass@200之间的相对改进来得出这一结论,详细情况可以参见图6。
尽管熵是常用的多样性衡量指标,但由于多种原因,它并不能完美地反映大型语言模型(LLM)的多样性。因此,团队采用了一种新的方式,通过对所有生成的程序使用简单的配对策略,将它们置于思路空间中计算多样性。具体的算法细节可以查看原论文。






Cursor的突破确实令人兴奋,但在实际应用中,如何平衡模型的准确性和多样性仍然是个挑战,值得进一步探讨。
Cursor的规划搜索方法很有前景,但我担心在实际编程中,模型能否始终提供准确且多样的代码输出,还有待验证。
Cursor的研究确实有突破,但希望他们能加强对模型多样性的评估,确保在实际应用中不会出现过于相似的代码输出。
对Cursor的多样性提升方法很感兴趣,但我觉得在实际开发中,如何确保模型输出的代码不仅多样而且实用,仍需更多案例支持。
Cursor在代码生成上的新方法很有趣,但我希望能看到更多实际应用的案例,尤其是如何保证输出代码的质量与实用性。
Cursor的新方法很有潜力,但我觉得具体如何提高代码生成的质量和实用性,还需要更多实际案例来验证。
Cursor的新方法让人期待,但真正能否在复杂项目中有效提升代码质量还有待观察,希望能有更多成功案例分享。