小结:宝剑锋从磨砺出
基本情况:
百度在国内算是为数不多坚持开发原生多模态模型的团队之一。文心一言5.0在11月发布时,凭借两万亿的模型规模引起了广泛关注,但一周后Gemini 3 Pro的亮相,让大家看到了多模态技术的更高水准。毕竟,北美的资源环境让他们培养出来的模型,确实不是国内团队能靠努力和算法轻易追赶的。不过,这并不意味着百度的方向就是错的。
经过两个月的打磨,文心一言5.0的正式版虽然没有实现质的飞跃,但在认真解决了预览版的一些问题后,整体的可用性有了明显提升,稳稳地在国产模型的第二梯队站住了脚。
虽然Token的使用量增加了18%,但平均耗时基本没有变化。两万亿的模型在推理时依然有些吃力,这恐怕短期内难以解决。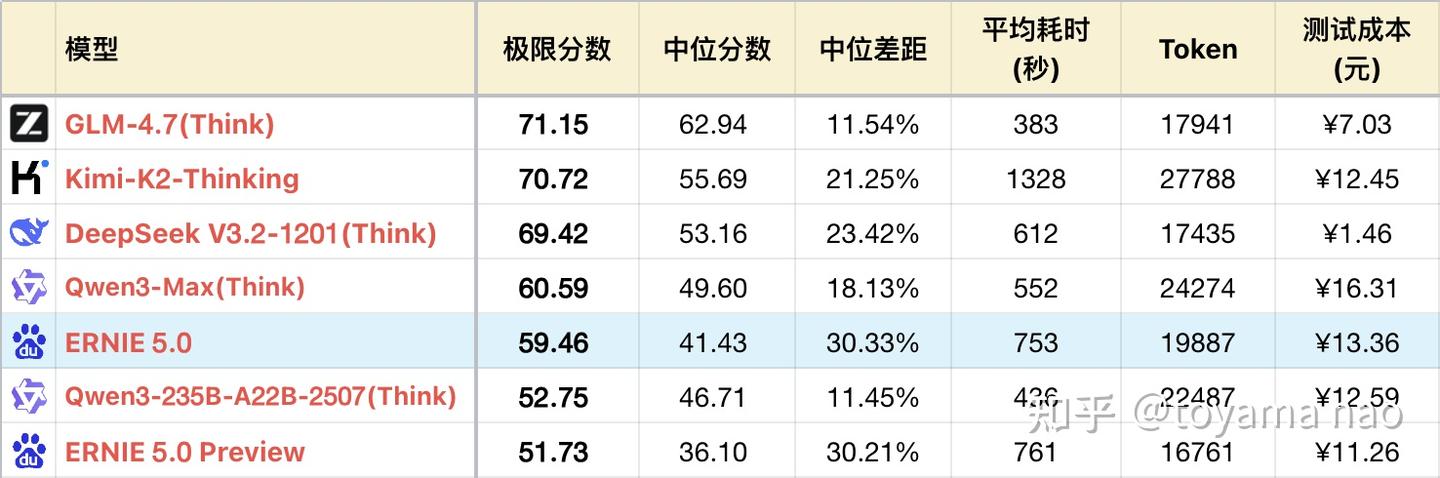
基本情况:
百度在国内算是为数不多坚持开发原生多模态模型的团队之一。文心一言5.0在11月发布时,凭借两万亿的模型规模引起了广泛关注,但一周后Gemini 3 Pro的亮相,让大家看到了多模态技术的更高水准。毕竟,北美的资源环境让他们培养出来的模型,确实不是国内团队能靠努力和算法轻易追赶的。不过,这并不意味着百度的方向就是错的。
经过两个月的打磨,文心一言5.0的正式版虽然没有实现质的飞跃,但在认真解决了预览版的一些问题后,整体的可用性有了明显提升,稳稳地在国产模型的第二梯队站住了脚。
虽然Token的使用量增加了18%,但平均耗时基本没有变化。两万亿的模型在推理时依然有些吃力,这恐怕短期内难以解决。
逻辑表现:
*1 表格中只展示了部分可对照模型,以便突出对比关系,并不是完整的排序。
*2 题目及测试方法详见:大语言模型-逻辑能力横评 25-12月榜,新增#55题。
*3 完整榜单更新请查看 https://llm2014.github.io/llm_benchmark/
相比11月的预览版,正式版在以下几方面有了明显改进:
改进:
- 长链推理:正式版在长链推理方面的准确率和稳定性明显优于预览版,可以进行更长时间的推理。预览版在处理复杂问题时,Token消耗平均也不会超过36K,而正式版最高能达到61K,接近MaxToken的限制。这意味着在需要穷举推理的问题上,正式版的表现更为出色。不过,对于需要技巧的题目,提升幅度却不明显,还可能因为过于思考而浪费Token和时间。
- 计算能力:正式版的计算能力整体上优于预览版,简单运算的准确率也很高,稳定性好。小数计算的精度大约在4位,超过这个范围就可能因为误差累积而出错。在科学计算方面,正式版的劣势还是挺明显的。
- 指令遵循:正式版在直接遵循指令的能力上稍微强于预览版,在相关测试中,遵循的比例也普遍高于预览版。不过,这并不意味着完美,经过多次尝试后随机性会偏高,实际应用中可能会出现“失控”的情况,或者需要额外提示词来引导模型的输出。
- 多轮能力:正式版在多轮对话能力上明显优于预览版,后者通常在运行7到8轮后就会遗忘最初的提示,而正式版可以稳定运行超过30轮。在猜词测试中,正式版凭借丰富的世界知识能够猜出一些较为冷门的词汇。不过也有不足,比如在一开始用二分法推进,但中途会突然改变思路,深入某个领域,碰壁后才再回到二分法上,这也显示出正式版能够及时调整方向的能力。
- 写作:预览版因为推理能力不足,虽然知识面广却难以发挥。而正式版在写作任务上有了一些改善,输出的格式更加规范,但文风上有点“有限的发散”。与DeepSeek的奇妙比喻相比,文心在严肃主题的写作上较为严谨,而在需要开脑洞的话题时,也不会走得过于偏离。
不足:
- 上下文幻觉:预览版的幻觉问题不算乐观,正式版的改善也有限,30%的中位数差距就能看出端倪。之前预览版存在的一些问题,正式版基本上也还有,部分题目得分有所分化。比如#42题需要从文本中提取多个数字,预览版可能会得高分,而正式版却很难得分。在#41题中,预览版完全没理解题意,而正式版对部分内容有了理解并能给出正确回答。文心的幻觉问题,除了可能与设定温度偏高有关,也与其偏文科的调教风格有关。
赛博史官说:
如果想要成为一家优秀的大模型公司,就得对未来有自己的看法,并为之付出持续的努力。Anthropic的使命是解决白领工作场景中的所有高价值内容,因此Claude系列在编程、数据分析和写作领域表现突出。而OpenAI则希望通过大模型推动人类科技的进步,所以GPT系列在逻辑推理和数据分析上遥遥领先。
虽然百度在过去三年的大模型竞赛中可能有些迷失方向,但文心5.0无疑是一个训练有素的新起点,具备不错的基本功、足够的智力水平、稳定的多轮能力以及丰富的世界知识。这让文心有机会在日益激烈的多模态模型竞争中占有一席之地。不过,单有实力可不代表有应用场景,百度若能清晰定义文心的未来,那这样的未来也许会给百度带来微笑。
所有评测文章均在公众号:大模型观测员同步更新。
声明:
文章来自网络收集后经过ai改写发布,如不小心侵犯了您的权益,请联系本站删除,给您带来困扰,深表歉意!







听说文心一言5.0比之前的版本好多了,具体改进有哪些呢?
文心一言5.0的长链推理能力真不错,感觉能处理复杂问题了。
看到文心一言5.0的表现,感觉国产模型在进步。
文心一言5.0在多轮对话上有明显提升,能稳定运行超过30轮,这意味着什么呢?
二分法推进的思路很有趣,文心一言5.0在复杂思维的调整上显示出灵活性,这点值得点赞。
文心一言5.0的多轮对话能力强,能稳定运行超过30轮,真是个好消息,适合长时间交互。
看到Token使用量增加了18%,真有点小担心,这会不会影响性能呢?