整理 | 华卫
最近,知名的人工智能公司 Cognition 发布了全新的高速 AI 编码模型 SWE-1.5,这款模型是为了让软件开发工作变得更加高效而设计的,目前已经可以在 Windsurf 代码编辑器中使用。今年 7 月,Cognition 还收购了开发工具 Windsurf,这也为这款新模型的推出铺平了道路。
他们还表示,得益于与推理服务提供商 Cerebras 的合作,SWE-1.5 的运行速度最高能达到 Anthropic 的 Sonnet 4.5 模型的 13 倍,这可真是个了不起的成就。
你没听错,SWE-1.5 比 Sonnet 4.5 快了整整 13 倍,编码性能几乎达到了顶尖水平。Cognition 在官方声明中提到,“开发者不必在速度和质量之间选择”,这也是 SWE-1.5 设计的初衷。
SWE-1.5 拥有数千亿的参数,是一款经过专门设计的前沿模型,旨在克服之前提到的速度与质量之间的矛盾,提供卓越的性能和速度。它的一个显著特点就是运行速度,这得益于与 Cerebras 的深入合作,双方一起优化了 SWE-1.5。具体来说,他们通过训练一个经过优化的模型来实现更快的解码,并构建了一个优先级系统,使得与智能体的互动更加流畅。
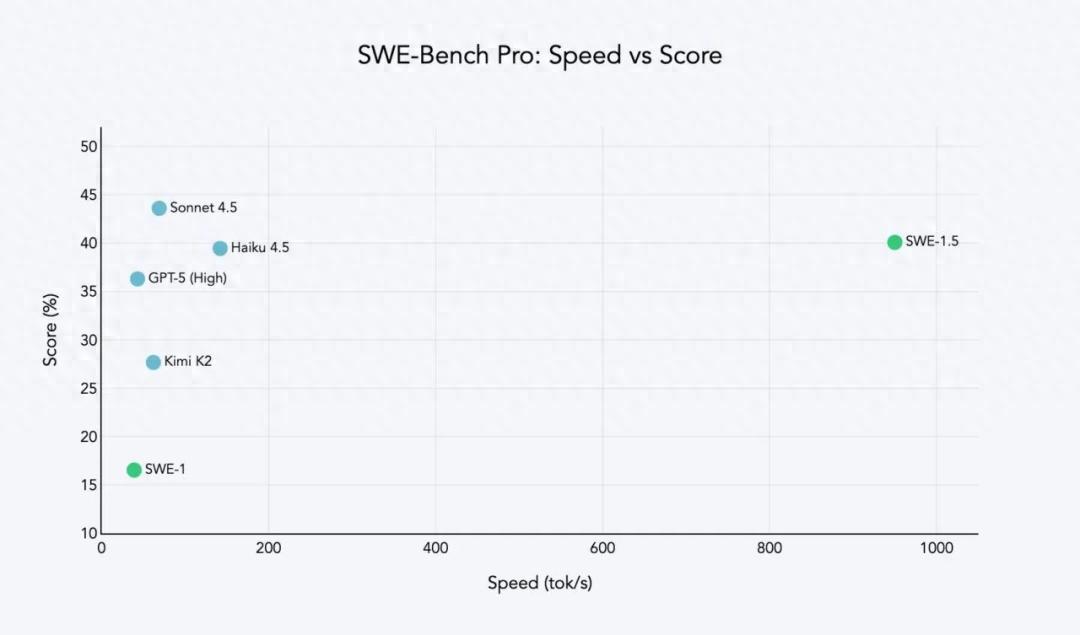
Cognition 表示,这次合作使 SWE-1.5 的延迟表现极佳,并“树立了新的速度标准”,最高处理速度可达 950 token/秒,这比 Haiku 4.5 快了 6 倍,比 Sonnet 4.5 快了 13 倍。这样一来,以前需要 20 秒的任务,现在只需 5 秒就能完成。Cognition 认为,5 秒是避免“半异步死亡谷”的关键时间点。
当模型的处理速度达到 950 token/秒时,以前的系统延迟变成了主要障碍,因此 Cognition 重新审视了 Windsurf 智能体的实现细节。他们重写了代码检查和命令执行的核心组件,将每一步的操作时间缩短了最多 2 秒。Cognition 表示,未来会继续投入优化工作。
在 Scale AI 开发的 SWE-Bench Pro 基准测试中,Cognition 的 SWE-1.5 模型取得了 40.08% 的好成绩,仅次于 Claude 的 Sonnet 4.5(得分为 43.60%)。此外,SWE-1.5 还致力于提供更好的用户体验,在高速运行时实现了接近当前最佳水平的编码性能。

Cognition 表示,目前许多工程师已经将 SWE-1.5 作为日常工作利器,应用场景包括深入分析和理解大型代码库;轻松编辑全栈应用程序的配置文件,而无需记忆字段名称。值得一提的是,Cognition 正在测试的 Codemaps 功能就是由 SWE-1.5 提供支持的。
2 基于新一代 GB200 芯片训练,设计全新编码环境
支撑 SWE-1.5 背后的是巨额的基础设施投资。Cognition 表示,这款模型的训练依赖于“由数千颗英伟达 GB200 NVL72 芯片组成的先进集群”,并声称它可能是“首个基于新一代 GB200 芯片训练的公开生产级模型”。GB200 一经推出便被称为“性能怪兽”,与同数量的英伟达 H100 Tensor Core GPU 相比,GB200 NVL72 在 LLM 推理任务上性能提升最高可达 30 倍,同时成本和能耗降低最多 25 倍。
今年 6 月,该团队首次获得新硬件的使用权限时,固件尚在完善中,这使得团队需要从零开始建立更可靠的健康检查和容错训练系统。对于需要微调模型以应对现代软件工程中复杂、多步骤任务的密集型强化学习(RL)技术来说,这套强大的硬件至关重要。
在训练方法上,Cognition 使用自己定制的 Cascade 智能体框架,通过端到端的强化学习来完成模型训练,并利用数千颗 GB200 NVL72 芯片的集群。
Cognition 认为,RL 任务中的编码环境质量是影响模型性能的关键。因此,他们手动创建了一个数据集,力求在 Devin 和 Windsurf 的真实场景中还原任务与编程语言的多样性。基于开发 Devin 的经验,他们在评估体系上投入了大量资源,并与顶尖工程师、开源项目维护者及技术负责人合作,设计了高保真的编码环境。
需要注意的是,SWE-1.5 是首次尝试通过这种环境来提升模型的编码能力,环境中设置了三种评分机制:经典测试(如单元测试、集成测试)用于验证代码的正确性,评分标准用于评估代码质量和实现思路,智能体评分则是通过可浏览器的测试产品来评估完整性。为了防止“奖励作弊”,他们还开发了一个名为“奖励强化”的流程,通过人类专家寻找绕过评分标准的方法。
3 从 Windsurf 的“余烬”中,诞生新战略
新款SWE-1.5模型发布,Cognition的新战略和市场反应
最近,Cognition推出了SWE系列的新成员——SWE-1.5,这款新模型是基于Windsurf项目的迭代成果。最初,Windsurf项目是由早期团队于2025年5月启动的,不过OpenAI最终并未成功收购这个项目,于是Cognition顺势接手。现在,他们把SWE-1.5整合到了Windsurf的开发环境(IDE)中,正在逐步实现新的愿景。
值得一提的是,SWE-1.5并不只是一个单一的模型,而是一个整体系统,涵盖了模型本身、推理过程以及智能体框架,旨在达到高效与智能的完美结合。“选择一个编码智能体,不仅仅是选择模型本身,其周围的调度系统也会对模型的表现产生重大影响。在开发Devin时,我们常常希望模型与框架能够无缝协作;而通过这次SWE-1.5的发布,我们终于实现了这个愿望。”Cognition在公告中提到。
所以,SWE-1.5的开发过程主要包含以下几个关键环节:
-
基于顶尖的开源基础模型,在我们自定义的Cascade智能体框架下,进行真实任务环境中的端到端强化学习(RL)训练。
-
在模型训练、框架优化、工具开发和提示词工程等方面不断进行迭代。
-
在必要的情况下,从零开始重写核心工具和系统,以提升速度和准确性(当模型速度提升10倍时,很多环节可能成为瓶颈)。我们计划在这个领域持续推进,相关改进也将提升Windsurf中其他模型的性能。
-
高度依赖真实场景的“内部测试使用”(dogfooding),这能帮助我们围绕用户体验来优化智能体与模型,而通用的奖励函数则无法做到这一点。
-
部署多个测试版本的模型(称为“Falcon Alpha”),并对性能指标进行严格监控。
这样的战略使得SWE系列模型得以快速迭代,Cognition似乎在赌,即使没有推出市场上参数规模最大的模型,这种高度集成和快速的使用体验也能吸引一批忠实用户。
4 SWE-1.5与Composer,你怎么看?
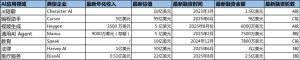
就在SWE-1.5发布的同时,AI编码环境工具Cursor也推出了其高速模型Composer。两家公司都在努力打造专属模型,来提升高度集成、低延迟的开发者体验,并希望减少对第三方接口(API)的依赖。这也显示出人工智能开发者工具市场正在向同一方向发展。
两家公司都在大规模应用强化学习技术。Cognition使用了名为otterlink的虚拟机管理程序,在数万个高保真的并发环境中进行强化学习推演,这些环境除了代码执行还有网页浏览功能。这种方法与Cursor所描述的、为自身强化学习训练“运行数十万个并发沙盒编码环境”的方式非常相似。
这种技术路径也突显了一个共识:要打造真正高效的编码智能体,企业必须结合自有工具和真实场景来微调模型。Cursor的一位机器学习研究员对此表示:“如今,想要高效工作,至少需要具备一定的智能;如果能将智能与速度结合,效果会特别好。”
另外,两者还有一个共同点就是透明度不足。Cognition和Cursor都对新模型的基础架构保持神秘,只提到模型是基于“领先的开源基础模型”构建的。这种保密性让外部评估变得困难,只能依赖用户对公司内部测试的信任。这引发了不少猜测,有人认为SWE-1.5使用的开源模型可能是GLM-4.5,Composer也是类似的情况。
值得注意的是,公开信息显示,Composer的生成速度能达到每秒250个token,而SWE-1.5的处理速度最高可达950个token/秒,几乎是前者的四倍。
目前,已有一批开发者试用了这两款模型。AI专家兼博主Simon Willison在测试SWE-1.5后表示:“这款模型确实感觉非常快,与Cerebras的合作进行推理是个明智之举。”不过,也有用户反映,在使用这两款模型后发现,“SWE-1.5虽然速度快,但未能解决某个问题;而Cursor 2.0的Composer-1模型却一次性解决了该问题(在5-codex连接失败的情况下)。”

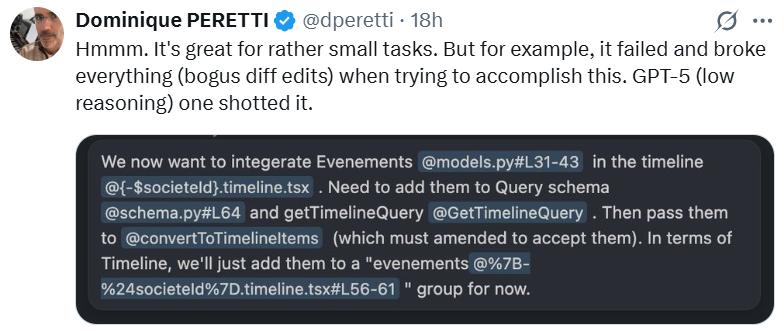
还有用户指出,“(SWE-1.5)在处理小型任务时表现得确实不错。但是比如在尝试完成某项任务时不仅失败了,还搞砸了所有东西(出现了无效的差异编辑),而GPT-5(低推理版本)一次就成功完成了。”
参考链接:
https://cognition.ai/blog/swe-1-5
https://winbuzzer.com/2025/10/30/cognition-releases-windsurf-high-speed-swe-1-5-ai-coding-model-outpacing-gpt-5-high-xcxwbn/
声明:本文为AI前线整理,不代表平台观点,未经许可禁止转载。
今日好文推荐